Objective
In this study, we aim to examine the features of websites that can be used in determining the nature of the website i.e. is the website malicious or not. As such, to address the research objective we will need to conduct classification using a historic dataset.
Research Questions
To address the research questions, the following questions will be considered:
- What are the most important features that can be used to classify websites?
- What is the best model that can be used to classify different websites and what exactly are the differences in performance between these models?
- Is there a relationship between the features that can be used to classify the given websites?
Research hypothesis
Consequently, the research questions will be answered through testing the following three hypotheses:
Null 1: There is no difference between the adopted classification models
Null 2: There is no relationship between website features and the classification of websites either as malicious or benign.
Null 3: There is no relationship between different website features.
Previous/Related Contributions
The study of cyber security has been quite popular with the current widespread adoption of technology into human life ranging from private to government organizations. As a result, there have been a number of related studies which use various methods in analyzing possible sources of malicious tech activities. Mostly such studies are concerned with the effect of platforms which have the potential of affecting a large related audience i.e. malicious websites.
To understand the concept of websites and the effect that can be posed to users in case of vulnerabilities, we need to examine some basic literature which define the terminology behind.
Classifying web sites using URL
Most studies that use classification of websites using URLs, adopt a supervised a learning approach in reference to lexical structures. The URL method conducts classification of websites into malicious domains and normal (benign) domains by using features that are extracted using DNS communication. Some of DNS features as defined by (Ellingwood, 2014) are: Domain Name, IP Address, Top-Level Domain, Hosts, SubDomain, SubDomain, SubDomain, Zone File, and Zone File. Other studies have also used machine learning in classifying websites including works by (Urcuqui, Navarro, Osorio, & Garcıa, 2017).
A study by Christian Urcuqui which can be found on kaggle https://www.kaggle.com/xwolf12/malicious-and-benign-websites evaluates various classification models to conduct a prediction of malicious and benign websites based on, “…application layer and network characteristics” (Urcuqui C. , 2018).
The dataset by Urcuqui (2018) contains the following features:
URL, URL_LENGTH, NUMBER_SPECIAL_CHARACTERS, CHARSET, SERVER, CONTENT_LENGTH, WHOIS_COUNTRY, WHOIS_STATEPRO, WHOIS_REGDATE, WHOIS_UPDATED_DATE, TCP_CONVERSATION_EXCHANGE, DIST_REMOTE_TCP_PORT, REMOTE_IPS, APP_BYTES, SOURCE_APP_PACKETS, REMOTE_APP_PACKETS, APP_PACKETS, DNS_QUERY_TIMES, TYPE.
In his work, (Urcuqui, Navarro, Osorio, & Garcıa, 2017) notes obtains a 100% classification accuracy of the Random forest classifier which is the only model they use.
Their results also show that the URL is the most important feature when classifying a website, results which are mostly in line with the ones we obtain from our analysis.

Comparison study
Classifying using IP addresses
Kanazawa, Nakamura, Inamura, & Takahashi (2017) using IP addresses to classify websites develop a classifier that is tested using the following procedure to test for its effectiveness:
Unlike the results obtained in our study, in their study, Kanazawa, Nakamura, Inamura, & Takahashi (2017) note that the nature of the IP address can be effectively used to determine if the website is malicious or benign.
Cyber Security
With the recent spiraling of reported cases related to cyber security threats, the question of what are the potential sources of security loopholes in any organization have been commonplace. According to an article by (Institute of Chartered Accountants in England and Wales, 2018) the most commonly listed sources of cyber security vulnerabilities include: ransomware, Phishing, hacking, data leakage, and insider threat.
Malicious websites have grown to become major cyber threats (Xu, 2014) which are to a better part of technological operations inevitable hence require only that organizations adopt adequate solutions to detect and protect oneself against them. In relation to the study by Xu, Joyce Tammany in her article correctly asks, “…How can you keep your website safe when one million new malware threats are created every day?” (Tammany, 2018).
Malicious and Benign Websites
A study done by (Kanazawa, Nakamura, Inamura, & Takahashi, 2017) proposes the use of address features of network address class as means of classifying unknown malicious websites. Other methods developed to prevent web users from navigating to malware infected websites include: web reputation systems which detect malicious sites, feature URLs, as well as IP address features.
Since this study is mainly focused on the application of classification of URLs to classify websites into either being malicious or benign, most of the literature focuses on URLs as compared to IP features.
Preprocessing activities, Features Selection / Engineering
In this section, we conduct data preprocessing which will mainly involve handling missing observations then carry out feature selection.
Generally, the dataset contains 1779 observations.
Data Cleaning
Given that this project will adopt a classification model, we need clean up the dataset as well as determine which features/variables are relevant in the classification of the type of website.
A quick examination of the dataset reveals that it contains some 814 missing observations.
To ensure improved accuracy we deal with the missing observations through imputing the values in the CONTENT_LENGTH attribute.
After cleaning the dataset and examining the features for variable importance, we obtained the following variable importance plot:
From figure 1, we note that URL, SOURCE_APP_BYTES, DIST_REMOTE_TCP_PORT, and SOURCE_APP_PACKETS are the top four most important features of the dataset.
Partial Plots for the top five most important features
Transformation
Some of the variables caused the model to fail hence, selection of features was conducted after transforming the string and object variables in the dataset using encoding to obtain integers which were then accepted by the model.
Selection of the features
In order to determine the most important features to use when predicting the class of a website, we examined the score of each of the features as given in the results of the random forest classifier.
Feature interactions
In examining the association between the features and the target attributes, we note that URL feature has the highest correlation with the target (Type) variable with a Pearson correlation coefficient of 0.57.
Training Method(s)
Given that our original dataset is labeled, we opt for a supervised machine learning model with a specific application of classification instead of regression so that we can adopt a model to accurately classify the type of the website as either malicious or benign. Hence, we used three models i.e. random forests, K-nearest neighbor and a Naïve Bayes classifier. However, as for the training, we only used the XGBoost training method and split the dataset in the ratio 80:20 then applied the three models individually to the datasets.
After training the models, we then conducted simple ensemble learning using max voting method which conducts multiple predictions on the data points which is generally useful in calculating probabilities in classification problems (SINGH, 2018) and assumes that each prediction from the models is a vote. In addition, we ensemble the models using bagging method. This way, we get to compare the accuracy of each model before conducting prediction using the best classifier.
From assembling the models, we note that of the ensemble methods, the bagging classifier has the highest accuracy i.e. 98.77% while the voting method has an accuracy of 96.23% both of which are higher than the accuracy scores of: Knn model (91.94%).
Among the tricks used, the use fact that we split the programming section to include a modelling section, library importing section improves the loading time of the chunks containing the classification models. Further, the use of both classification metrics and model accuracy score enables us to carryout extensive comparison between the models. This, kind of sets this project apart from the rest.
Another trick that sets this project aside is the fact that before training the dataset, we chose to segregate the target attribute leading to better training after sampling.
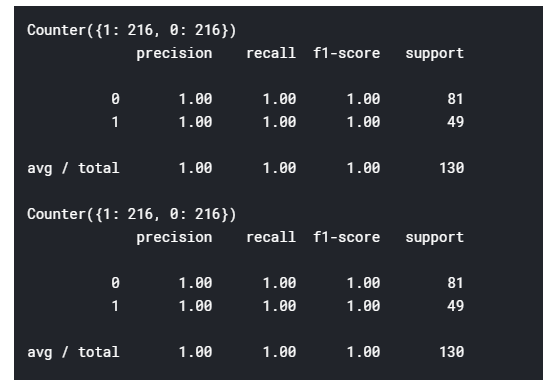
When selecting only the top five features as obtained from the variable selection plot, we note that the classification accuracy for each model subsequently increases. Hence, the features that would get 90-95% of your final performance are: URL, SOURCE_APP_BYTES, DIST_REMOTE_TCP_PORT, SOURCE_APP_PACKETS, and REMOTE_APP_PACKETS which gives us a 100% accuracy score and a 100% score of the confusion matrix performance metrics for the simplified random forest classifier as shown in the table below:
Accuracy metrics reporting, charts, Model Execution Time
In this section, we present the classification metrics for the three models as well as the ensemble models used in the classification problem presented in this paper as well as other graphs used to measure the performance of the models and the time taken for each model to be executed.
Random Forest
Naïve Bayes
kNN (k- Nearest Neighbors)
Area Under curve for each of the five models
Discusion of the classifiction metrics results
From the above section, we can develop the following table to compare the time taken, accuracy, and area under curve for each of the models:
| Model | Time taken | Performance accuracy | Area Under Curve |
| Random Forest | 0.046875 | 100% | 1 |
| Knn | 0.01526 secs | 91.94% | 0.788 |
| Naïve Bayes | 0.0001 secs | 97.85% | 0.987 |
Based on the performance metrics presented above, we can base our choice of model on three features i.e. time taken for execution, performance accuracy or the area under curve. When considering the time taken for execution, we note that Naïve Bayes takes the least time implying that if we base our metrics on time, then Naïve Bayes would be the best model however, the random forest classifier has a higher performance accuracy of 100% and an area under the curve of 1 with an execution time of 0.046875 seconds.
The simplified model of the random forest however takes approximately 0.03125 seconds which is a slight improvement from the original random forest classifier but still maintains it high performance.
Use of ensemble methods
As mentioned in the previous section, we used a complex and simple ensemble models i.e. bagging and voting models respectively on the three classification models.
The results of the ensemble models are given below:
Voting Ensemble model
Bagging ensemble model
| Model | Time taken | Performance accuracy | Area Under Curve |
| Voting ensemble | 0.1406 secs | 96.24% | 0.970 |
| Bagging ensemble | 0.03125 secs | 98.77% | 0.974 |
Of the two ensemble models, the bagging model has a higher classification performance of 97.4% which is slightly higher by 0.04% from the accuracy of voting ensemble model.
Summary
In summary, this paper uses three classification models to conduct the classification of the type of websites, the results indicate that the use of random forest would produce the most accurate results which will increase the probability of us classifying accurately the different websites into the two defined classes (0-benign, 1-malicious). Moreover, we note that the most important feature that can be sued to classify a website is the URL.
To succeed in our classification, we used a XGBoost training method and later used the obtained training and test sets in the three classification models i.e. random forest, knn, and Naïve Bayes. After training the models, we conducted an ensemble of the models in order to determine if we could improve the performance of the models. However, in as much as the performance of the ensemble models were slightly higher than that of Knn and Naïve Bayes, the random forest classifier still had a relatively higher accuracy score.
We used Jupyter notebook and python version 3.7 to conduct all the coding for this paper. In relation to time, the models took an average of between 0.00 and 0.14 seconds to execute.
References
Ellingwood, J. (2014, February 18). An Introduction to DNS Terminology, Components, and Concepts. Retrieved from Digital Ocean: https://www.digitalocean.com/community/tutorials/an-introduction-to-dns-terminology-components-and-concepts
Institute of Chartered Accountants in England and Wales. (2018, May 23). Top five Cyber Risks. Business Advice Service, pp. 7-9.
Kanazawa, S., Nakamura, Y., Inamura, H., & Takahashi, O. (2017). A Classification Method of Unknown Malicious Websites Using Address Features of each Network Address Class. International Workshop on Informatics , 261-288.
SINGH, A. (2018, June 18). A Comprehensive Guide to Ensemble Learning (with Python codes). Retrieved from Analytics Vidhya: https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/
Tammany, J. (2018, November 5). What Is Malware and How Can It Affect My Website? Retrieved from SiteLock: https://www.sitelock.com/blog/what-is-malware/
Urcuqui, C. (2018, June 12). Malicious and Benign Websites. Retrieved from Kaggle: https://www.kaggle.com/xwolf12/malicious-and-benign-websites
Urcuqui, C., Navarro, A., Osorio, J., & Garcıa, M. (2017). Machine Learning Classifiers to Detect Malicious Websites. CEUR Workshop Proceedings, 1950, 14-17. Retrieved from https://ieee-dataport.org/documents/malicious-and-benign-websites
Xu, L. (2014). DETECTING AND CHARACTERIZING MALICIOUS WEBSITES. San Antonio: University of Texas.