Overall Goals / Research Hypothesis
The main aim of this project to be implementing and analysing on the hypothesis test they can used for the data fields contents that are includes the uuid, author, language, published , domain rank , and spam score and number of data to be predicts on the result to finding and evaluating on the python. The python estimating on the dataset analysing to have been used on the fake news on the data field’s analysis. The Initial stages of the python evaluation they have to importing and preparation on the training data to be accessing on the python to find the predictive value on the plotted graph on the analysing dataset. After that to importing the data to be finished and running on the training dataset on the python code implementation. The implementation on the python code to be directly access on the training dataset and to eliminate on the dummy dataset. The analysing on the data to be predict the result of the dataset on the training data to be processing and preparing the data to be finding the result to be prediction on the structure on plotting the graph on the python console running code. The scientific research on the hypothesis test they can used for the specified on the predicting result analysis on the statement will be implemented (Allen, Campbell & Hu, 2015). The implementation and analysis on the training data of the hypothesis to be used on the relationship between the two are more variables on the educated on the training dataset. The importing on the training dataset and to finding the original hypothesis on the testing classification of the displaying result successful on the hypothesis will be investigated.
Summary
The evaluation on the python code they have been used on the data science they can used on the data fields on uuid, author, language, published , domain rank , and spam score on the dataset analysing and implementation. The main coding parts on the programming language to be used on the two parts that are includes the R and python code on the learning and training dataset on the data science approaches to be used on the analysis which is very easy and simple way (Crippa & Orsini, 2016). The analysing on the training dataset and importing on the python they can used on the excel spreadsheet on the data library to be used and Initial analysis the data format and to predicts the pre-processing on the data series evaluation. The identification on the SciPy and NumPy analysis which is used on the analysing data techniques on the scenic equivalent they can performed on the classification on the continuous data manipulation of the R implementation on the temporal dataset that are include the fake dataset on the language, published , domain rank specification. The dataset on the data fields analysis they can used of the python code implement which is used for the very helpful on the all the developers and easy to importing the data to be easy to predicts and they to finding the result on the development of the backend process they can used on the different ways that are includes the scientific computing, artificial intelligence, and web development on the displaying the result analysis to be verified and easy to build the games and application on the starter to be used on the python code implementation which is very helpful to others and easy to predicts the result in very simple ways implementation (Guo & Chakraborty, 2010).
Features Selection / Engineering
The feature selection on the python code implementation they can used for the text analysing tools and which follows the methods on different format that are include the TF-IDF, vectors counts analysis, and title models on the word embedding process implementation. After they can implementing process on the stages that are present the work to exact and using the very advance feature techniques. The selecting on the feature prediction which have to implement on the variable analysing method on the output which is highlighted of the information to be learned on the highly predict model on the independent analysing process on the displaying output analysis of the system which is highlights. The implementation on the pre-paring steps they can used for the selecting on the different strategies to be display on the utility on the output which is presenting on the normal way on the Artificial intelligence calculation. The highlights on the display on the result variable to be used on the measurement on the hypothesis test variable on the chosen method implementation. Feature decision is for isolating in separating immaterial or repetitive highlights from your informational dataset. The key distinction between feature assurance and extraction is that segment decision keeps a subset of the primary features while incorporate extraction makes new out of the fresh out of the box new ones.
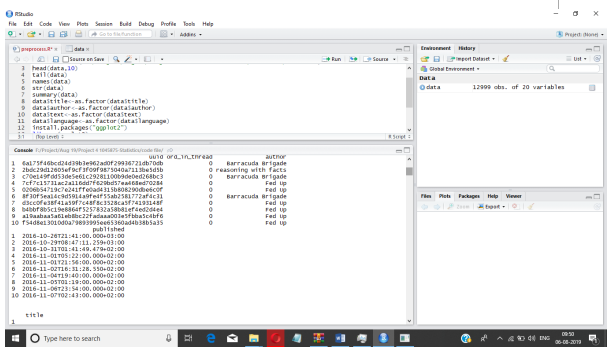
To import the fake news dataset on R studio and separate head and tail data. In this dataset, convert from numeric to factor format which used to plot the graph.
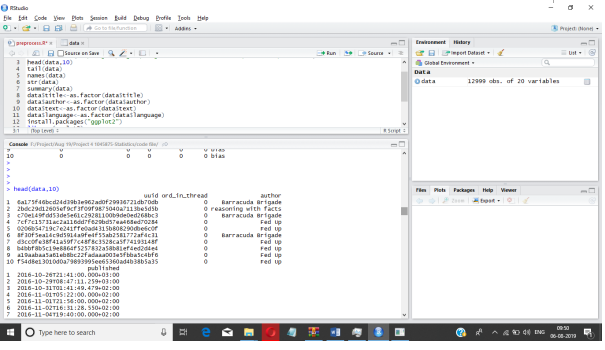
It shows the head data from fake news dataset.
Training Method(s)
The training method on the python implementation to be initial stage on the process on first importing on the data that are includes the some data fields that are include the uuid, author, language, published, domain rank, and spam score and training method of the dataset analysis implementation. The AI used to preparing strategies and that expansion language for applications (Hamilton & Ferry, 2018). To introduce the bundles for preparing techniques and plot the chart for that dataset. We utilized the motion picture rating dataset.
For execute and examination the dataset. It contains the motion picture name, year, spam score and language author. To set up the information and investigation the information. To Compare the dataset and plot the diagram among met spam score information .To look at each dataset and plot that information chart. Man-made reasoning and AI on the implementation process using PC to get readied using a given instructive gathering, and use this readiness to envision the properties of a given new data (Hill & Pitt, 2016). Planning procedures were kept the equal between both of our hypothesis, requesting the tweet itself and outstanding on the record. Since we end up with an equivalent data structure, a TF-IDF vector, we can simply support that into the train_test_split work and get our characteristics to continue into the classifiers. Some segment of the issue here pushed toward getting to be getting a dataset that contained enough of the two spotlights on that the classifier would give an average return. Since the target of the under taking was to perform NLP, the determination of classifiers attempted to stick around things that would work characterization with that. Credulous Bayes, Linear Support Vector Machine, and Logistic Regression were by and large cantered to attempt to portray our model. While those capacity outstandingly in their own special accords, bunch was furthermore attempted with a limit set to dataset through burdens on it to see which would give us the most bewildering and implementation on the running code. The three classifiers used in the social event strategy was Logistic Regression, Naïve Bayes, and Random Forest Classifier. Another troupe technique that was used was the Random Forest Classifier beside with a greater estimators than what was used for the averaging/weighting gathering. The testing dataset was kept at 30% planning and after that 70% was left for testing with the discretionary state set.
Interesting findings
To utilize the measurable techniques to appraise the precision of the models and it make on concealed information. To evaluate the information or given dataset and assessing the dataset. We have used R code for find the accuracy result and using the dataset. We have used the fake news dataset which contains author name, text, language, domain rank, spam score and replies count. First step to prepare the data and that used for training the dataset. The training dataset are used to predict the dataset. We have used the R code for analysis the data and pre-processing the dataset. We will utilize the information and predict the dataset using algorithm. To using the best model for implement the dataset and that processing the fake new dataset. We have analysis the data based on news rank, spam score and replies count. The data split on the two different dataset such as training dataset and validation dataset on process the dataset. The different values that are 80% dataset performed on the training data and 20% dataset performed on the validation (Iverson, 2014). The main concepts is to implement the machine learning concept for implement the dataset and using the R code. To plot the graph for each numerical data based on given dataset.to be directed configuring the dataset and use of learning algorithm to find the training data. The first step to prepare the data that means import the dataset on R code and that eliminate the duplicate data from dataset.
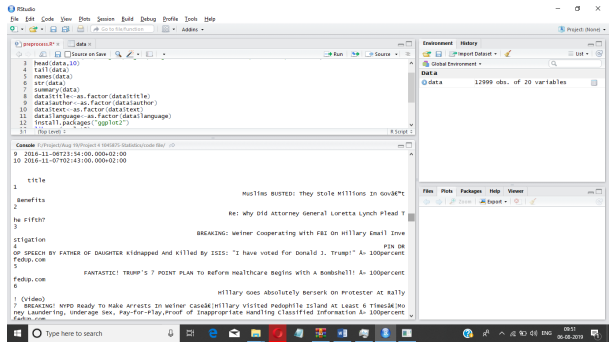
It display the tail of given dataset and shows all data field.
> summary(data)
uuid ord_in_thread author
0005c47ed182eccb3351a9cf79557057cc390ad5: 1 Min. : 0.0000 :2424
00150c8aa5429fad97aad8edcfd0d5992bb19a0c: 1 1st Qu.: 0.0000 admin : 247
0020136d33e150ef507f1c37851bd4aba92a4faa: 1 Median : 0.0000 Alex Ansary: 100
0021a18f1aa21c410e9b2cad2d9968d9cb85d9a0: 1 Mean : 0.8915 Eddy Lavine: 100
002d6589ca649f6eae2136537769f80b4ba69d45: 1 3rd Qu.: 0.0000 Editor : 100
00334dad5edac7951269bedac9441ae8e0294514: 1 Max. :100.0000 Gillian : 100
(Other) :12993 (Other) :9928
published
2016-10-27T03:00:00.000+03:00: 59
2016-10-26T03:00:00.000+03:00: 37
2016-10-28T03:00:00.000+03:00: 34
2016-11-01T02:00:00.000+02:00: 30
2016-10-31T11:00:00.000+02:00: 25
2016-11-03T02:00:00.000+02:00: 21
(Other) :12793
language crawled site_url country
english:12403 2016-10-26T22:16:26.842+03:00: 2 abeldanger.net : 100 US :10367
russian: 203 2016-11-08T01:28:01.428+02:00: 2 abovetopsecret.com: 100 GB : 831
spanish: 172 2016-10-26T21:03:37.215+03:00: 1 activistpost.com : 100 RU : 400
german : 111 2016-10-26T21:03:37.507+03:00: 1 ahtribune.com : 100 DE : 224
french : 38 2016-10-26T21:03:38.206+03:00: 1 amren.com : 100 FR : 207
arabic : 22 2016-10-26T21:03:39.196+03:00: 1 amtvmedia.com : 100 TV : 201
(Other): 50 (Other) :12991 (Other) :12399 (Other): 769
domain_rank thread_title
Min. : 486 WH Press Secretary Says Obama’s Denial About Clinton Server Was ‘Entirely Factual’: 44
1st Qu.:17423 Caught On Tape: ISIS Destroys Abrams Tank With Anti-Tank Missile : 43
Median :34478 Duterte: Philippines Will Not Be a ‘Dog Barking for Crumbs’ from U.S. : 38
Mean :38093 Five Terrifying Things From Trump’s Blueprint for His First 100 Days if Elected : 36
3rd Qu.:60570 Tesla Earnings Smash Expectations After Dramatic Change In Reporting Methodology : 26
Max. :98679 Fears Grow Julian Assange Was Extradited On ‘Guantanamo Express’ : 19
NA’s :4223 (Other) :12793
spam_score
Min. :0.00000
1st Qu.:0.00000
Median :0.00000
Mean :0.02612
3rd Qu.:0.00000
Max. :1.00000
To plot the graph for domain rank and spam score that shows the plot for given value.
Simple Features and Methods
The target and target attribute contains the training dataset and that using the algorithm for implement the models. The training dataset get from the preparing data and that providing algorithm with training dataset. The algorithm used to implement the training dataset and that give the input attributes which provide the capture (Polasek, 2011). To analysis the dataset which used to pot the graph for given dataset. The method are implement y the data pre-processing model and classify the data. We can anyway exchange off on various strategies to process the information itself like utilizing distinctive stemming techniques or letting in certain numbers. The pre-processing method used to implement the data analysis and display the accurate result. If one the data to be stored on the training dataset and that perform the hypothesis test. In this method predict the data and test the all data from given dataset. We can anyway exchange off on various strategies to process the information itself like utilizing distinctive stemming techniques or letting in certain numbers. The pre-processing implementation on the data to be performed and display the result and once the data to be stored on the training on original hypothesis after that to be first implementing on the test on the hypothesis to be predicts the values on the first file.
Model Execution Time
The dataset based on fake news dataset and using the minimal model that performance on the dataset for pre-processing services. First step to process the dataset was used to send a file.so that it only had to be done once. To initially analysis on the entire dataset format using model which used perform the execution time. The dataset format convert to processing format and that use to statically analysis structure (Wegman, 2012). To finding on assemble on the average weighting they can used for classification methods on the linear and naive Bayes regression methods. They can performed which is predicts and supporting on Random Forest classifier, average weight random assembling, and vector machine implementation they can displaying on the result of hypothesis to be successfully implementing which provides the original and added value hypothesis test.
References
Allen, G., Campbell, F., & Hu, Y. (2015). Comments on “visualizing statistical models”: Visualizing modern statistical methods for Big Data. Statistical Analysis And Data Mining: The ASA Data Science Journal, 8(4), 226-228. doi: 10.1002/sam.11272
Crippa, A., & Orsini, N. (2016). Multivariate Dose-Response Meta-Analysis: ThedosresmetaRPackage. Journal Of Statistical Software, 72(Code Snippet 1). doi: 10.18637/jss.v072.c01
Guo, R., & Chakraborty, S. (2010). Bayesian adaptive nearest neighbor. Statistical Analysis And Data Mining, n/a-n/a. doi: 10.1002/sam.10067
Hamilton, N., & Ferry, M. (2018). ggtern: Ternary Diagrams Using ggplot2. Journal Of Statistical Software, 87(Code Snippet 3). doi: 10.18637/jss.v087.c03
Hill, H., & Pitt, J. (2016). Statistical Analysis of Numerical Preclinical Radiobiological Data. Scienceopen Research. doi: 10.14293/s2199-1006.1.sor-stat.afhtwc.v1
Iverson, J. (2014). Statistical Form amongst the Darmstadt School. Music Analysis, 33(3), 341-387. doi: 10.1111/musa.12037
Polasek, W. (2011). Using R for Data Management, Statistical Analysis, and Graphics by Nicholas J. Horton, Ken Kleinman. International Statistical Review, 79(2), 284-285. doi: 10.1111/j.1751-5823.2011.00149_11.x
Wegman, E. (2012). Special issue of statistical analysis and data mining. Statistical Analysis And Data Mining, 5(3), 177-177. doi: 10.1002/sam.11151