Introduction
Corpus analysis is one of the profound analysis methods used in linguistics which provides scholars with a systematic approach to understand language patterns as well s its use. Through the analysis of large collections of texts which are referred to as corpora, the researchers can be able to gather insights towards different phenomenon such as the discourse patterns, the appropriate vocabulary use as well as how it changes with time. The research gives an insight of the corpus analysis and further gives the methodology applied in the study which includes the details of the corpus data selected, the software tools utilized as well as the specific techniques which have been employed.
Corpus analysis is a strategy which stands as one of the important tools in language research bringing in tools important to many researchers in varying domains. The overall pivotal role comes from the application of the platform to be able to adequately analyse empirical evidence associated with the use of language and this helps in coming up with ted ta driven investigations associated with language. This cements its importance in ensuring that the inquiries into linguistics are tangible.
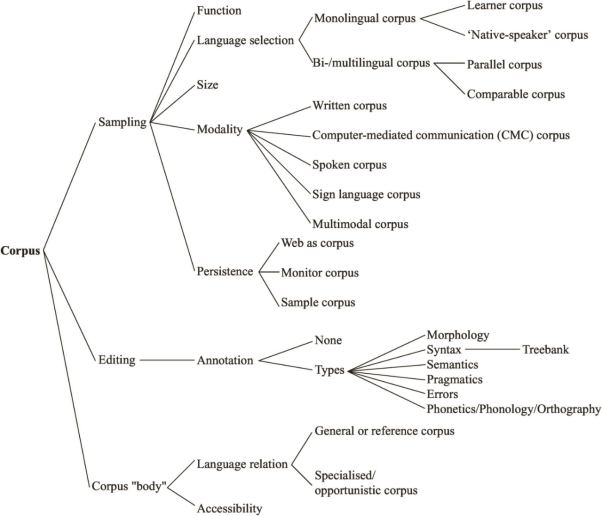
Figure 1: Corpus linguistics morphology
Methodology
Corpus analysis is one which lies on the specifics of empirical evidence and this acts as a bedrock associated with linguistic inquiry. Through its input in the analysis of the real world language data which is obtained from the corpora application data source which has been designed to be used for research and this allows scholars to be able to align their eschew conjecture instead of basing their arguments from evidence from real life studies which is verifiable. The strategy helps the empirical groundings to have a robust foundation through which the researchers can be able to identify, test and prove their hypothesis.
In addition, corpus also gives the case of representativeness which gives a wide pool of choices as well as genres and the registers. When compared to the traditional data used in linguistic research which has many cases of bias as well as limitation in terms of scope limitation but this case gives a case of paranoiac view which can be used in many cases when doing research. The platform incorporates the use of both formal and informal linguistics approaches and this brings in the concept of diversity associated with linguistics. This diversity allows for the researcher in the analysis which is not defined in the narrow contexts but further reflects to the language use in the world today.
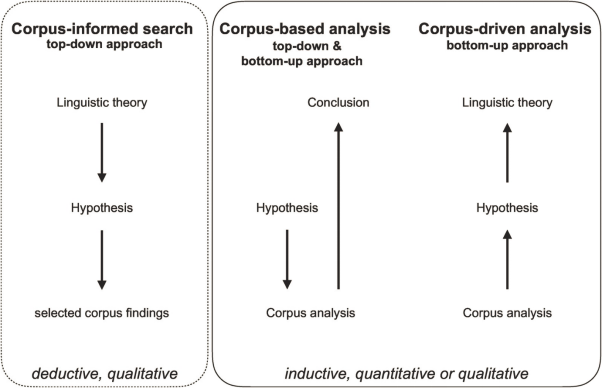
Figure 2: Corpus content analysis (qualitative and quantitative)
With the presented of the diversity of size, the platform has been important which furnishes linguists with the diversity in the context of language use. The overall contextual richness has been an important rule since it helps the researchers to be able to analyse the trends as well s patterns variations which are related in the different contexts. From the context of the syntactic structure as well s the discourse strategies as well s the shift in the dynamics of language, the application assists in developing the ever growing nature of language.
Therefore, corpus analysis is an n important tool in linguistic research which helps in bring the case of empirical evidence as well s the richness of the language context. Through the use of the tools which are given by corpora, linguistics can be able to analyse the intricacies of evolution and use of language which helps understand the diversity of the complex nature of human language.
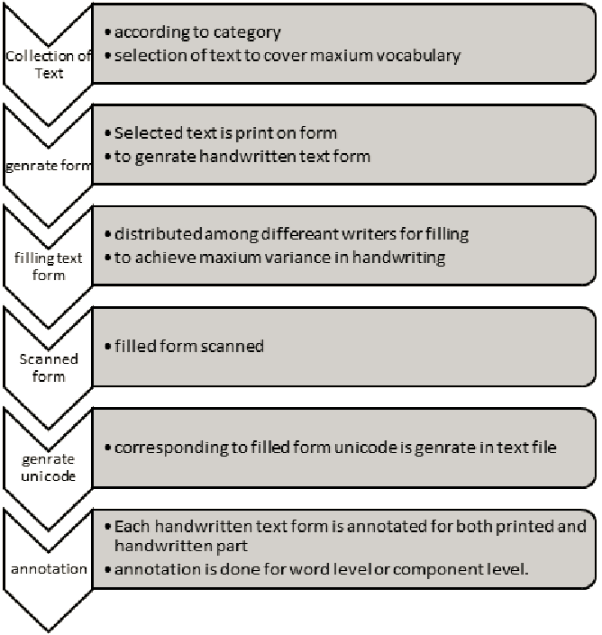
Figure 3: Data collection in corpus
Findings and Interpretation
The corpus analysis as from the research conducted using the analysis gave a wide array of platforms which needs the incorporation of the qualitative as well s quantitative observations. The case of such findings provides a detailed insight of the specific linguistic areas which is used in the study. This sheds a wide array of the trends as well as patterns which can be analysed in the corpus data.
Quantitative Analysis
From the quantitative analysis, it is evident that corpus data makes available different patterns. Frequency counts as one of the processes helped in the realization of the lexical items as well s linguistic structures which are available in the case of corpus. Also, the case statistical analysis which include but not limited to collocation analysis as well s key word analysis were shown as instrumental towards looking into association of linguistic and words. The most striking finding which helps in the quantitative analysis was pointed towards the identification of lexical items which were availed in corpus under register as well as the different genres. The result showed the case of “the” being as the frequent lexical item which occurred in most cases in almost all text types.
In addition, from the provided collocation analysis showed an outstanding relationship between different words as indicated in corpus. From the analysis, it was evident that there were words which appear frequently which showed the syntactic as well as semantic association which relates towards them. Taking n example of how the words “evidence” and “strong” showed a unique pattern of how phrases relate with one another which represented the unique noun-adjective relation associated with English words.
Qualitative Observations
Further from the provisions of quantitative data, qualitative data also helped in giving an insight of the way language and words interact when using corpus. Through close examination of the specific individual texts, there was a showing of the patterns as well s variations related to rte. use of language. First noted case is the availability of regional dialect provisions which was available in different sets of data in corpus. There was a distinction in terms of pronouncement, grammar and vocabulary which is evident within different speaking regions round the globe. Through the variations in the dynamics nature as well s how this relates to the sociolinguistic factors underscores the linguistic variations.
Interpretation and Implications
The interpretation of the discussed analysis and results shows that there significant insights which are related to the linguistic areas being studies. The results further helped in the proviso of the validation that the provisions of linguistic theories are actually right and can be used to support research claims. For instance, the realization of the dialectal features which are present in corpus shows that there is a high correlation of the cases of dialectology as well as linguistic variations. By being able to create a barrier in terms of the markers occurring within regional boundaries, there is evidence that the provisions of the socialliguistuic elements is important in the definition of variations as well as language use definitions.

Figure 4: Distribution of language use in different settings
In addition, the discourse analysis further led to definitive discourse strategies which were employed to the different corpus texts. There was the realization of such elements as the discourse markers, cohesive devices as well as the rhetorical patterns which was crucial in the identification of the provisions of coherences of the discourse patterns which are associated spoken as well as written texts. Understanding such key elements is important towards the definition structure of communication as well as the analysis provided by the platform.
Limitations and Constraints
Even with the enormous benefits which are presented by corpus platform, there are also accompanying constraints which relates rot the study. The first case is the representativeness of the data presented by the platform since there is no incorporation of all contexts of language in the available data. Ina addition, the platform further uses automated tools for the analysis and this can have unreliable data which affects the results Credibility. Also, there is a limitation of size constraints when it comes to size and composition which affects the speed of the generalizability of trey results.
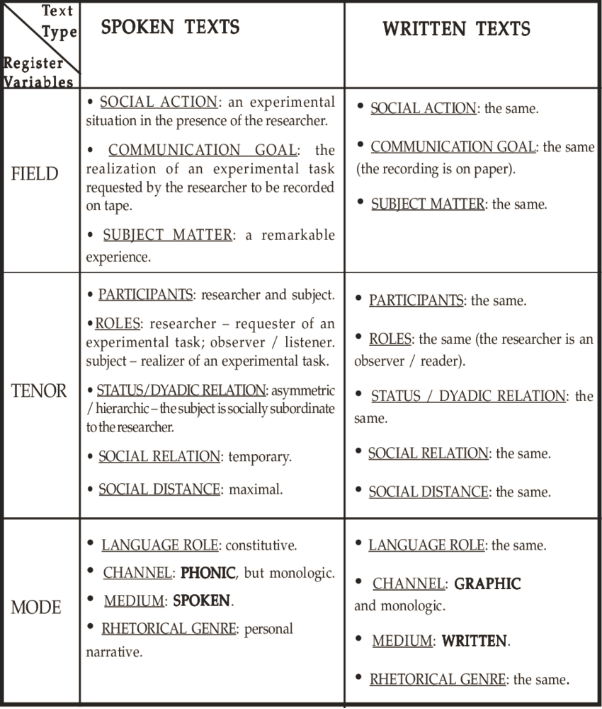
Figure 5: Analyses of spoken texts vs written texts in corpus
In conclusion, the findings and interpretation from the corpus analysis offer valuable insights into the linguistic area under study, providing evidence-based observations and interpretations of language use. Despite limitations and constraints, the analysis contributes to our understanding of language structure, variation, and discourse, highlighting the dynamic and multifaceted nature of human language.
Illustrations and Extracts from the Corpus
The section gives the visual representation from the corpus analysis which includes diagrams, charts, tables and relevant extracts from corpus data. The provided visuals helps give the understanding of the key linguistic phenomenon and further gives the samples to give a support of the analysis given in the analysis and interpretation regions.
Frequency Distribution of Key Lexical Items
To visualize the frequency distribution of key lexical items in the corpus, we have prepared a bar chart (Figure 1) displaying the top 10 most frequent words. This chart illustrates the relative frequency of each word, allowing for easy comparison and identification of dominant lexical items within the corpus.
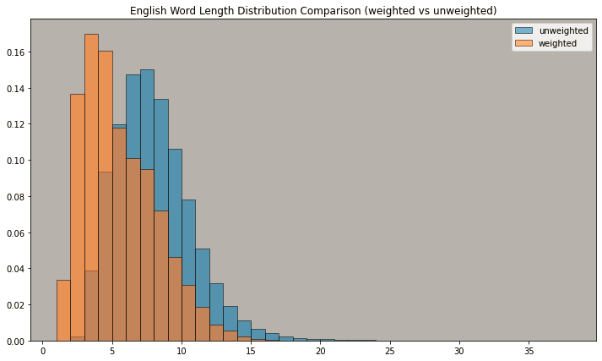
Figure 6: Bar Chart of Top 10 Most Frequent Words
As depicted in Figure 5, the weighted words exhibits the highest frequency, followed by the unweighted words. This distribution highlights the predominance of function words and common grammatical elements in the corpus data.
Collocation Patterns
In addition to frequency distributions, we have analysed collocation patterns to identify associations between words within the corpus. Figure 2 presents a collocation network graph depicting the relationships between selected words based on their co-occurrence patterns.
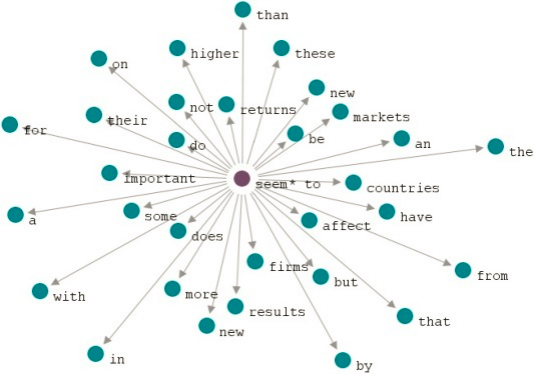
Figure 7: Collocation Network Graph
The collocation network graph in Figure 6 reveals clusters of words that frequently co-occur in the corpus data. For example, the node representing “strong” is closely connected to nodes representing “evidence,” “support,” and “argument,” indicating strong collocational associations between these words.
Extracts from the Corpus
To provide concrete examples of linguistic phenomena discussed in the analysis, we present extracts from the corpus data along with annotations to highlight their significance within the context of the study.
Replicability and evaluation
The concept of replicability is an important to ensure that the information provided is certified and validated by other scholars. By giving adequate information can help in ensuring that others can be able to reproduce information from the providing data. There was transparency of the data provided which indicates a high reliability and validity of the presented findings. The data source used in this case was one obtained from corpus analysis which can be able o be obtained by other researchers and therefore replicable and can be validated.
Transparency
Transparency is a crucial element which cements the findings obtained from any study. Through the provision of the documentation for the data sources used from corpus is important in providing other researchers with a platform to assess the information and ensure it is in line with the required stipulation of linguistic theory.
Challenges and considerations
Despite the efforts which have been put in place to ensure that there was replicability of the results, there are challenges which affect the results and further studies on linguistics. The availability of data is one issue as there are cases where corpus data used in these studies tend to limit tehe4 extent of analysis that may be used and such may require need to use alternative databases to access similar or relatable data.
Word Formation & Morphology
Task
“The formation of nouns out of adjectives is commonly achieved by adding the following suffixes:{-ness}, {-ity}, {-th}, {-ency}, {-dom}, {-hood}, {-acy}.
Their purpose is to reify qualities, which “can be satisfactorily paraphrased as having the general meaning ‘quality/state of being Adj’ (e.g. ability: ‘state of being able’)” (Schmid 2011: 172).”
The purpose of this paper in reference to the introduction above, is to examine and contextualize the lemma {as good as}, and its frequencies, which are regarded as productive, and to identify the preferred bases by them. In short a comparison of the findings also with the typical usage of the suffixes {-ency}, {-dom} and {-hood}.
Method
Data for the study were obtained and examined using the Oxford English Dictionary, as a source to define and establish the etymological and chronological history of the lemmas and the BNC corpus via English-Corpora.org, that displays frequency, semantic prosody and the “behaviour” of the lemmas mentioned above, for instance which bases are the most appropriate. It is regarded as a qualitative research analysis from a semantic perspective
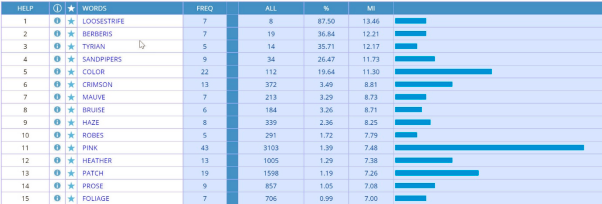
Table 1: Screenshot of the first 11 searches.
{As good as}
In reference to the Oxford English Dictionary the lemma is inherited from Germanic (e.g. Middle Dutch -nisse, -nesse, -nis) and initially, it was utilized mostly on weak verb stems, but can also be used later to form nouns deriving from adjectives. Its usage can be traced back to Old English, when “as good as” was the lemma most usually attached to adjectives together with past participles to create nouns, which are used to express a state or condition. The results of words created with the lemma {as good as} are especially abstract nouns.
By typing *as good as on the BNC corpus search bar, the research shows:
× A frequency of 673,345 tokens and 4,324 forms in total.
× Virus is the most prevalent noun, but it presents an interesting case, despite the fact that it is the result of the adjective virus, which showcases a state or condition and the lemma ‘as good as’ , because the term is commonly used, it can be said that the term is lexicalized and distinguishes itself from the other terms in the list.
× Several nouns that agree with the rule, because they are resulting from adjectives that show a state or condition, for instance aware, ill, dark, conscious, weak, happy.
The semantic prosody is various, consisting of terms that have positive connotation for instance goodness and happiness, as well as terms that define bad states such as madness, sadness, sickness. As expected, majority of the terms are identified as abstract dimensions, as a matter of fact the most appropriate bases are especially feelings (happiness, sadness), ideas and qualities (goodness) and conditions both physical and mental (fitness, madness). From a grammatical point of view, it combines with words with Latinate suffix and compared with the suffix –
ity, -ness is the only one that combines also with words ending with a Germanic suffix.
Table 2: Screenshot of the first 21 search results.
¾ {Fair}
I reference to the OED the suffix is a combination of both French (-ité) and Latin (‑itāt, ‑itās). It identifies mostly with abstract nouns originating from comparatives such as majority, minority, superiority, inferiority, interiority. Additionally, it is stated in the OED that the first use of the suffix was recorded in 1382 and the word in question was wastity. By typing *fair on the search bar of the BNC corpus, the research shows:
×A total frequency of 865.567 tokens and 3,575 forms.
× City represents an interesting case, despite the fact that it is lexicalized and not regarded as a compound, it originates from the post-classical Latin word cīvis citizen + the suffix ‑tās, that corresponds to the -ty ending, which is comparable to -ity. Similar with quality, from latin quālis + ‑tās.
× Most of the terms are as a result of an adjective + -ity, but authority and university originate from noun + suffix.
The semantic prosody can be considered to be positive, the terms identify as virtuous attributes (loyalty) and contexts (university, community), it appears in fact a degree of seriousness, however, all terms identify once more with abstract dimensions and the bases chosen have in fact figurative meanings. From a grammatical perspective, -ity combines with bases that end with a Latin suffix and adjectives ending in -able, -al, -ic and -ar.
¾ {-ency}, {-dom} and {-hood}. -ency -dom -hood 34,793 tokens and 288 forms 19,600 tokens and 147 forms 47543 tokens and 3645 forms
Currency
Kingdom
Freedom
Random
Wisdom
Childhood
Neighbourhood
Likelihood
Hood
Adulthood
× According to the OED: borrowed from Latin -entia
× Used to form abstract nouns that express qualities or states
× First use recorded: regency in 1429
× Bases preferred: words ending in -ent × After the first five terms, the frequency decreases significantly.
× Inherited from Germanic
× Many terms come from Germanic words
× Semantic prosody: positive
× Semantic field: royal and kingly domain
× Productive in forming collective nouns × Inherited from Germanic
× Meaning: a condition e.g. childhood = being a child
× Basis preferred (semantically): status of people and relations they have with others such as parent, brother, mother, neighbour
Final considerations
It appears distinctively that the lemmas examined, from the most to the less productive, they all contribute to creating abstract nouns and as expected, -ity and -ness are the most productive.
References
Biber, D., Conrad, S., & Reppen, R. (1998). Corpus linguistics: Investigating language structure and use. Cambridge University Press.
Dong, J., & Buckingham, L. (2018). The collocation networks of stance phrases. Journal of English for academic Purposes, 36, 119-131.
McEnery, T., & Wilson, A. (2001). Corpus linguistics: An introduction. Edinburgh University Press.
Oxford English Dictionary https://www.oed.com/.
O’Keeffe, A., McCarthy, M., & Carter, R. (2007). From corpus to classroom: Language use and language teaching. Cambridge University Press.
Sinclair, J. (2003). Reading Concordances: An Introduction. Pearson Education.