Executive summary
The fundamental objective of this undertaking they can executing on the twitter content mining information investigation With the expanding prevalence of microblogging destinations, we are in the gathering and dissecting on the twitter information data blast will be finished. As of June 2011, around 200 million tweets are being created each day. In spite of the fact that Twitter gives a rundown of most well-known points individuals tweet about known as Trending Topics continuously, it is regularly difficult to comprehend what these slanting subjects are about. Consequently, it is significant and important to group these points into general classifications with high exactness for better data recovery. To address this issue, we order Twitter Trending Topics into 18 general classifications, for example, sports, governmental issues, innovation, and so on. We try different things with 2 methodologies for theme order; (I) the notable Bag-of-Words approach for content grouping and (ii) organize based characterization. In content based arrangement strategy, we develop word vectors with inclining theme definition and tweets, and the ordinarily utilized loads are utilized to order the subjects utilizing a Naive Bayes Multinomial classifier. In neural system based grouping technique, content mining characterization strategies we distinguish top 5 comparative subjects for a given point dependent on the quantity of regular powerful clients. The classifications of the comparative subjects and the quantity of regular powerful clients between the given point and its comparable themes are utilized to group the given subject utilizing a C5.0 choice tree student. Tests on a database of haphazardly chose 768 inclining subjects (more than 18 classes) show that characterization precision of up to 65% and 70% can be accomplished utilizing content based and organize based arrangement displaying separately.
Table of Contents
Social media analytics framework. 5
Social media analytics techniques. 6
Introduction
The main aim of this project to be implementing and analysing on social media twitter analysis text mining using SPSS modeller stream implementation. Twitter is a very famous microblogging webpage, where user look for convenient and social data, for example, breaking news, posts about big names, and slanting subjects. Clients post short instant messages called tweets, which are restricted by 140 characters long and can be seen by client’s devotees. Any individual who has other’s tweets posted on one’s course of events is known as an adherent. Twitter has been utilized as a vehicle for ongoing data scattering and it has been utilized in different brand crusades, races, and as a news media. Since its dispatch in 2006, the ubiquity of its utilization has been significantly expanding. As of June 2011, around 200 million tweets are being produced each day portrayal precision (70.96%) trailed by k-Nearest Neighbor (63.28%), Support Vector Machine (54.349%),decision tree classifier achieves 3.68 events higher exactness appeared differently in relation to the ZeroR example classifier. The 70.96% accuracy is commonly amazing pondering that we mastermind focuses into 18 classes. At the point when another subject winds up prevalent on Twitter, it is recorded as a slanting theme, which may appear as short expressions gives a normally refreshed rundown of inclining subjects from Twitter. It is extremely intriguing to comprehend what subjects are drifting and what individuals in different pieces of the world are keen on. Be that as it may, a high level of drifting points are hashtags, a name of an individual, or words in different dialects and it is regularly hard to comprehend what the slanting subjects are about. It is hence imperative to order these points into general classifications for simpler comprehension of subjects and better data recovery. The drifting subject names might be characteristic of the sort of data individuals are tweeting about except if one peruses the pattern content related will be investigated.
Purpose discussion
grouped tweets to a predefined set of nonexclusive classes, for example, news, occasions, sentiments, arrangements, and private messages dependent on creator data and space explicit highlights extricated from tweets, for example, nearness of shortening of words and slangs, time-occasion phrases, stubborn words, accentuation on words, money and rate signs, “@username” toward the start of the tweet, and “@username” inside the tweet. Presented a Wikipedia-based grouping procedure. The creators ordered tweets by mapping message into their most comparable Wikipedia pages and computing semantic separations between messages dependent on the separations between their nearest Wikipedia pages. Included metadata from outer hyperlinks for theme characterization on an online networking dataset. Though all these past works utilize the attributes of tweet writings or meta-data from other data sources, our system based classifier utilizes theme explicit interpersonal organization data to discover comparative points, and uses classifications of comparable subjects to order the objective point. Group tweet messages to distinguish whether they are identified with an organization or not utilizing organization profiles that are created semi-consequently from outside web sources. While all these past works order tweets or short instant messages into 2 classes, our work characterize tweets into 18 general classes, for example, sports, innovation, legislative issues, and so forth proposed characterization framework comprises of four phases: Data Collection, Labelling, Data Modeling, and Machine Learning. In our investigations, we utilize two information demonstrating techniques: (1) Text-based information displaying; and (2) Network-based information displaying will be executed.
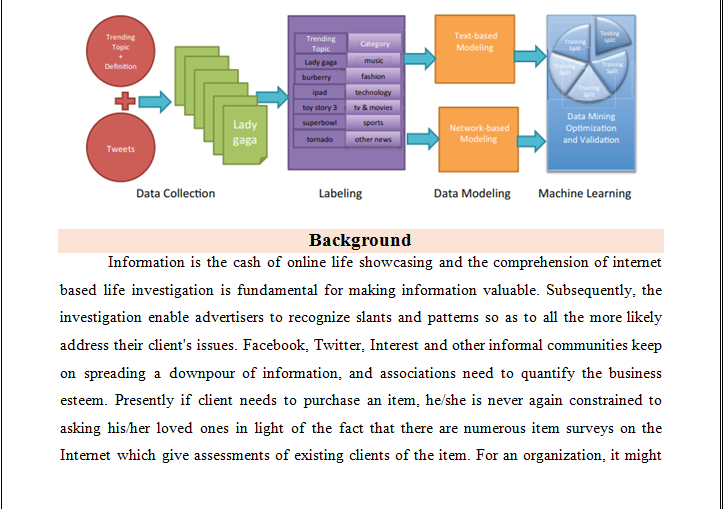
never again be important to direct studies, sort out center gatherings or utilize outer specialists so as to discover shopper suppositions about its items and those of its rivals on the grounds that the client produced content on the Web would already be able to give them such data. Organizations regularly battle to gauge buyer intrigue and to figure out what social information is really valuable for them to gather. By using estimation examination supplemented with human knowledge, organizations can sift through commotion and—with the assistance of AI innovation—distinguish the basic information that advances their business. The twitter online networking they can investigation the various stages that are incorporates the, web based life examination structure, web based life investigation methods, sorts of group of spectators, audit of information examination framework they can be utilized.
Social media analytics framework
The run of the mill structure includes three-organize process: catch, comprehend, and present ID of posts/tweets preceding the catch arrange this distinguishing proof is finished utilizing catchphrases which are controlled by clients. These catchphrases are then utilized in the computerized contents question solicitations to interpersonal organization’s API, Twitter API, gathers posts/tweets containing those watchwords. In this way, the means include: the recognize stage is the information getting to organize that includes distinguishing important watchwords to use in gathering internet based life information. At that point, the catch stage is the information cleaning step that includes getting important online life information by tuning in to different web based life sources, documenting significant information and removing relevant data, henceforth not all information caught will be valuable. Next, the comprehend which is the information investigation arrange that chooses significant information for demonstrating, expelling uproarious, low quality information, and utilizing different propelled information systematic strategies to examine the information held and gain bits of knowledge from it. At long last, the present is the information representation organize that manages showing discoveries from comprehend arrange in an important manner.
Concept of text mining
Social media analytics techniques
Numerous procedures can be utilized for internet based life examination. To begin with, the Supervised Classification, where the characterization is the partition or requesting of articles into classes. Content characterization is consequently relegate the writings into the predefined classifications. In this AI system, the classifier figures out how to arrange the classifications of records dependent on the highlights separated from the arrangement of preparing information. The administered arrangement incorporates: Support Vector Machine (SVM), Naïve Bayes, and Neural Network, K-closest Neighbor, and Decision tree, straight and nonlinear characterization. Run of the mill content characterization procedure has the accompanying advances: gather information, standardize information, dissect the information, train the calculation, test the calculation, and apply on the objective information. Commonplace content arrangement procedure has the accompanying advances: gather information, standardize information, break down the information, train the calculation, test the calculation, and apply on the objective information. The administered order incorporates: Support Vector Machine (SVM), Naïve Bayes, and Neural Network, K-closest Neighbor, and Decision tree straight and nonlinear characterization. Run of the mill content characterization procedure has the accompanying advances: gather information, standardize information, dissect the info information, train the calculation, test the calculation, and apply on the objective information. Second, Unsupervised Text Mining/Clustering: Text bunching is solo realizing, where no mark or target worth is given for the information. It is a strategy for get-together things or (reports) in view of some comparable qualities among them. It performs arrangement of information things only dependent on likeness among them. Most grouping calculations need to know the quantity of classifications in cutting edge execution.
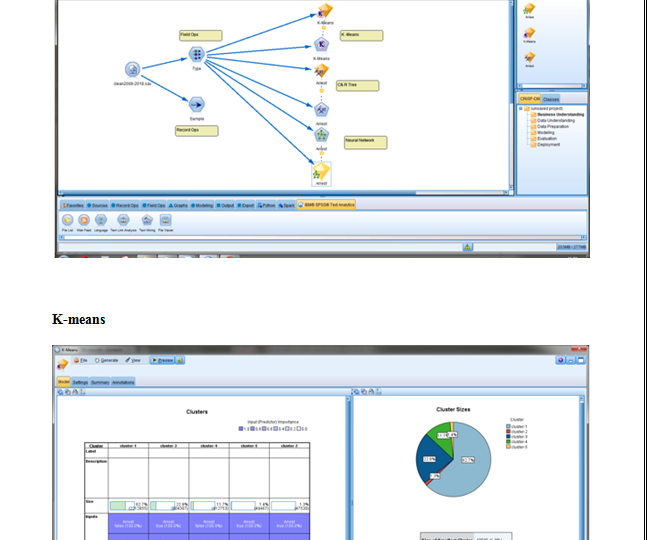
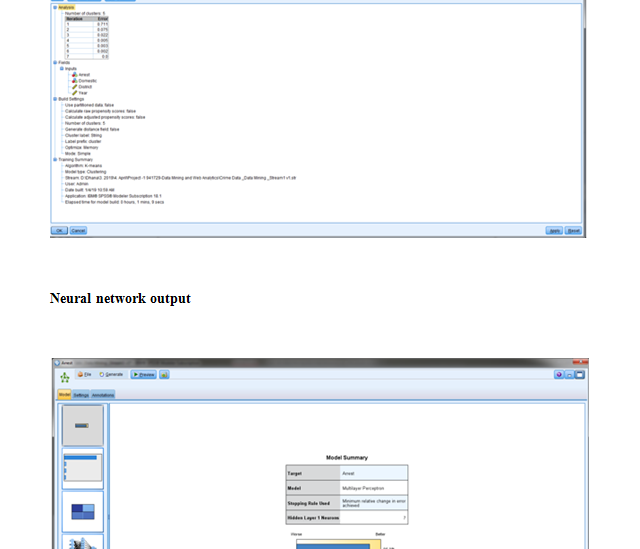
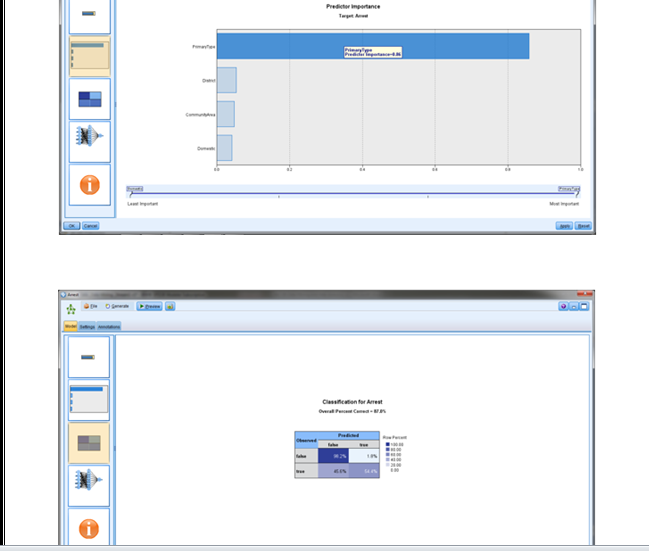
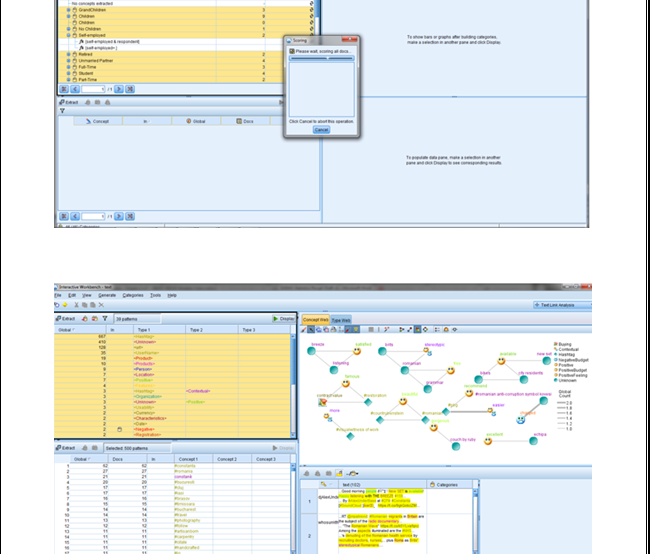
According to this paper (Batrinca and Treleaven, 2014) is composed for (sociology) specialists looking to investigate the abundance of web based life now accessible. It displays a thorough audit of programming instruments for interpersonal interaction media, wikis, extremely basic syndication channels, online journals, newsgroups, and talk and news channels. For culmination, it likewise incorporates acquaintances with web based life scratching, stockpiling, information cleaning and slant examination. Albeit chiefly a survey, the paper additionally gives a philosophy and a study of internet based life apparatuses. Investigating web based life, specifically Twitter channels for assumption examination, has turned into a significant research and business action because of the accessibility of online application programming interfaces (APIs) gave by Twitter, Facebook and News administrations. This has prompted a ‘blast’ of information administrations, programming apparatuses for scratching and investigation and online life examination stages. It is additionally an exploration zone experiencing fast change and development because of business pressures and the potential for utilizing online life information for computational (sociology) look into. Utilizing a basic scientific categorization, this paper gives an audit of driving programming instruments and how to utilize them to scratch, wash down and investigate the range of internet based life. Moreover, it talked about the necessity of an exploratory computational condition for online networking examination and shows as a representation the framework engineering of a web-based social networking (investigation) stage worked by University College London. The chief commitment of this paper is to give a review (counting code pieces) for researchers trying to use internet based life scratching and investigation either in their examination or business. The information recovery strategies that are exhibited in this paper are substantial at the hour of composing this paper, however they are liable to change since internet based life information scratching APIs are quickly changing on the content mining execution.
According to this paper (“Enhancing Social Customer Relationship Management by Using Sentiment Analysis”, 2017) Corporations have constantly wanted brief client experience criticism about their items for correcting current evaluating and approaches to remain in front of their rivals. A positive client experience can be made by investigating client assumptions and following up on them expeditiously. Informal organizations like Twitter speak to aggregate insight and assessment of the overall population and subsequently can be saddled for ongoing input. They have advanced as an asset for separating feelings for applications in different fields. Feeling examination can be utilized to acquire the general client experience of a huge client base on a constant. In this exploration, an aggregate of 153,651 unmistakable tweets for Twitter handle of 5 prevalent telecom marks in India: Ariel, Bharti Airtel, Idea Cellular, Reliance Jio and Vodafone India were removed for five months to build up a forecast model for telecom endorser expansion utilizing the supposition score. The outcomes were approved factually utilizing relationship examination. Positive client conclusions about the brand which they favour is reflected by higher development pace of new supporters included with that brand in the investigation time frame. The conclusion investigation results can be utilized by administrations to take convenient activities for improving the future client experience and staying away from client on the alternative content mining usage.
According to this paper (Wu and Ren, 2015) the web has experienced a social media informal organizations with huge measures of information being made and dispersed each moment. Twitter is one of the most well-known internet based life sites on the planet. Twitter’s speed and simplicity of distribution have made it a significant correspondence vehicle for individuals from varying backgrounds. The idea of network in this long range informal communication world has additionally gotten loads of consideration. Reading Twitter is helpful for seeing how individuals utilize new correspondence advancements to shape social associations, keep up existing ones, spread valuable data and realize social change. Since its initiation in March 2006, Twitter has come to more than 310 million month to month dynamic clients and on a normal more than 500 million tweets are sent for each day. “Tweets” are short messages with a most extreme length of 140 characters. Twitter is valuable since it is constant and data can arrive at an enormous number of clients in brief period. This makes is a considerably critical wellspring of data for information mining. In content based grouping technique, we build word vectors with slanting theme definition and tweets, and the regularly utilized id loads are utilized to characterize the points utilizing a Naive Bayes Multinomial classifier. In arrange based grouping technique, we distinguish top 5 comparable points for a given theme dependent on the quantity of basic compelling clients. The classifications of the comparative points and the quantity of regular compelling clients between the given theme and its comparative subjects are utilized to order the given point utilizing a C5.0 choice tree student. Investigations on a database of haphazardly chose 768 inclining subjects (more than 18 classes) show that grouping exactness of up to 65% and 70% can be accomplished utilizing content based and arrange based order displaying individually.
Conclusion
The principle objective of this task to actualize and examining via web-based networking media twitter information investigation utilizing SPSS modeller execution will be finished. We utilized two distinctive characterization plans for Twitter includes subject order. Aside from utilizing content based characterization, our key commitment is the utilization of interpersonal organization structure instead of utilizing simply printed data, which can be frequently uproarious given with regards to internet based life, for example, Twitter due the overwhelming utilization of Twitter language and the point of confinement on the quantity of characters that clients are permitted to create for their messages. Our outcomes show that neural system based classifier performed essentially superior to anything content put together classifier with respect to our dataset. Considering tweets are not as syntactically organized as normal report writings, content based characterization utilizing Naive Bayes Multinomial gives reasonable outcomes and can be utilized in situations where we will most likely be unable to perform arrange based examination. In our future work, we might want to incorporate content based grouping utilizing Naive Bayes (NBM) and system based characterization. The thought is coordinate these two classifiers to such an extent that on the off chance that we have every one of the five comparative points ordered, at that point use arrange based grouping generally use content based characterization. During our investigations we discovered a few points could fall under more than one class. Correlation of arrangement exactness utilizing various classifiers for organize based grouping. Obviously, best characterization exactness (70.96%) trailed by k-Nearest Neighbor (63.28%), Support Vector Machine (54.349%),decision tree classifier accomplishes 3.68 occasions higher precision contrasted with the ZeroR pattern classifier. The 70.96% precision is generally excellent thinking about that we arrange points into 18 classes. For instance, news about a renowned on-screen character’s account would fall under notions, amusements, study materials, motion pictures and books. Subsequently, we might likewise want to investigate the utilization of different names in arrangement will be completed.
Reference
Batrinca, B., & Treleaven, P. (2014). Social media analytics: a survey of techniques, tools and platforms. AI & SOCIETY, 30(1), 89-116. doi: 10.1007/s00146-014-0549-4
Enhancing Social Customer Relationship Management by Using Sentiment Analysis. (2017). International Journal Of Science And Research (IJSR), 6(12), 803-807. doi: 10.21275/art20178856
Wu, Y., & Ren, F. (2015). Exploiting opinion distribution for topic recommendation in Twitter. IEEJ Transactions On Electrical And Electronic Engineering, 10(5), 567-575. doi: 10.1002/tee.22120