1. Project Description
The main objective of this project is to predicting the certain categories of crime by using Chicago crime data. The prediction of crime data is completed by using Statistica Data miner and Text miner.
2. Dataset Description
This project uses Crime data which is collected by the Chicago police department which contains the information for different type of crimes, date, time, description and more. The data collection process is demonstrated below.

1. Prediction of Crime Data in STATISTICA
The prediction of the crime data using STATISTICA Data Miner of Feature selection method. To do feature selection in STATISTICA by follows the below steps,
The Feature selection in data miner is used to find out is what are the best predictors for types of crime, is it location type, is it because the crime does not result in an arrest (low deterrence factor), date, etc.
For this, we want to run a feature selection: 1. Go to Data Mining and click on Workspaces.
In work spaces, click on “Data” and select the “Crimes_Map” workbook and click Ok.
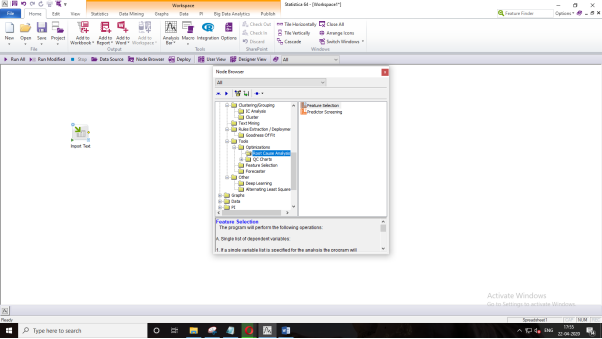
Click on “Node Browser,” and under “Data Mining,” select “Feature Selection Root Cause Analysis.”
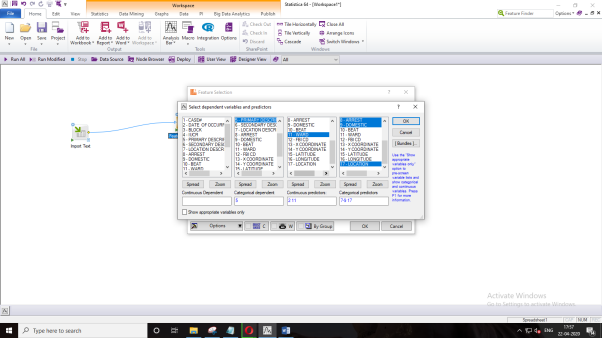
Click on “Variables.” Click on “Primary Description” as your dependent variable. This is the category for the type of crime happening throughout the city. For your independent or predictor variables, we will select “Date” and “Ward” for the continuous variables and “Location Description,” “Arrest,” “Domestic,” and “Location” for the categorical predictor variables. Click “Okay.” Then, click “Okay” again.

Right-click on the Feature Selection icon in the edit page and click on “Edit Parameters.” Select “All Result” and then click “Okay.”