FRACTIONAL KNAPSACK PROBLEM
Given n objects and a rucksack with a capacity weight of M. the object I has weight and profit.
Part a
For each object , a fraction and it can be placed in the knapsack, then the profit earned is The objective is to maximize profit subject to capacity constraint. To maximize,
which is subject to,
Part b
To determine the k and a set of n items:
For such that
And the following is maximized:
Part c
Part d
Part e
From the algorithm’s description it is clear that, for some t, the algorithm assigns to the first t−1 items, assigns part of item t’s weight to xt, and assigns 0 to all remaining items. Thus, the first part of the lemma holds. A straightforward induction shows that, at the end of the i-th iteration of the loop, . Since, by assumption, , the algorithm exits the while loop with i ≤ n. So,
Part f
For the n items, to consider a feasible solution of the fractional knapsack problems using the following algorithm,
Knapsack(P,W,X: arrayvals; M, n: int)
{
//the inputs are the increasing order objects such that the values of vi and ci to determine the //optimal solution in vectorized form.
For (i=1; i<=n; i++)
X[i]=0;
Capacity=M;
For (i=1; i<=n;i++)
{
if w[i]>capacity then exit()
cause overflow
else
x[i]=1; //greedy choice
capacity=capacity-w[i];
}
if i<=n then x[i]=capacity/w[i];
//choose a fraction
}
The optimal solution is a feasible solution that maximize. Knapsack problems appear in real-world decision making processes in different fields and they cut raw materials, selection of investments and portfolios and resources allocations.
COMPUTING NASH EQUILIBRIUM WITH SPECIFIC SUPPORT
The 2-person 0-sum games the payoff function f can be represented as follows,
When a player 1 chooses strategy for the payoff matrix, , and player 2 selects strategy , at this point the player 1 obtains the and the player 2 will get . It is used to determine the value of the game. The player 1 aims to maximize while the player 2 attempts to minimize this value. These players have 3 strategies to choose a row or to choose a column. The pure strategies are stated for a reason and the matrix is the payoff matrix for the different players. When a player opts to choose a given strategy before the other, for instance, player D chooses a strategy before player S, the guaranteed payoff is given for at least,
Choosing another strategy would imply that,
The implication of the game is that,
The results may be that the lower bound and the upper bound on the value of the game relate and the strategies are obtained as set values,
The pair of saddle point in the game is based on the pure Nash equilibrium where no players have the intention of changing game strategies for the undiscounted stochastic games. The Nash equilibrium is a solution for the multi-player games such that,
The BR in this case denotes the set valued best response mapping were the values are obtained as,
CONVERGENCE TO EQUILIBRIUM
The von Neumann’s theorem for a payoff matrix A and players choose a distribution among M and N strategies. The theorem of supporting the hyper-plane is given based on z, a point in B, with a distance to x as quite minimum. The point exists and is unique as B is closed and convex.
There is a condition provided such that,
And
The point exists and is uniquely closed and convex to B,
Proof of von-Neumann’s minmax theorem
Let X and Y be convex subsets of topological vector spaces, with Y compact, and let f be a real function on X and Y such that there is an upper semi-continuous and quasi-concave on X for a fixed subset,
And the lower semi-continuous and quasi-convex on Y for the fixed values,
This implies that,
It is given that,
Based on the corollary,
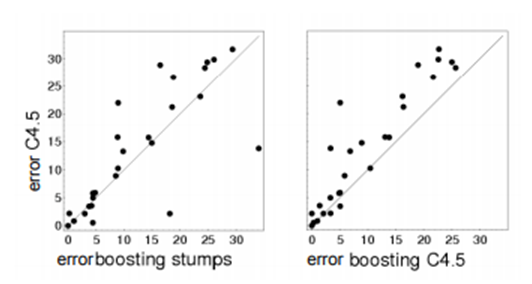
BOOSTING I: WEAK LEARNERS AND DECISION STUMPS
From the given dataset the weight of the set values is trained and interpretations are obtained. The training is done using Naïve Bayes to redefine count to be weighted count. The given values are obtained as,
To initialize,
The distribution is used as the train base learner using the distribution and the base classifier is given as,
A value is chosen from the set of real values,
The information is updated using the normalization factor to obtain the output and final classifier,
The AdaBoost based algorithm obtains a result as,
For the strong and weak classifiers, the AdaBoost attains a zero training error rate,