Aim:
This project’s aim is revolves around developing a data mining method, which ensures to help in the process of determining whether the restaurants are required to provide a couple of services namely the online meal ordering as well as booking the table to its customers for the Bangalore food assist (BFA). BFA refers to an Indian company which is connected with the Zomato restaurant search and the discovery site. In general, BFA helps the companies to provide the sample reviews of nearly 48000 restaurants, which comprises of the following attributes:
- Restaurant name
- Restaurant type
- Contact Number
- Location
- Address
- Neighbourhood
- Rate of visit
- Menu
- Cuisine and type of meals
- Average meal cost for the couple.
- Number of votes cast
- Liked dishes
- Reviews
Business problem
The aim of BFA is to gather few introductory insights of the restaurants in Bangalore, for exploring and to clean up the deliver their reviews in order to examine and create restaurant table’s classifier for their table booking, for ordering online and to decrease the classifications that are wrong. The tool named Rapid Miner is utilized for the development of BFA’s data mining method, and in the process of data mining this tool is highly essential. The restaurant reviews are explored and cleaned up with the help of Set role, Normalize, Selecting Attributes on a Rapid Mining data-mining tool.
For developing and exploring a classifier for the BFA restaurant for Booking a table service and online meal ordering service, the two classifications namely the Random forest and neural nets classifications are used to decrease the wrong classification. Thus, this report will briefly discuss and analyse the above mentioned areas. The analysing on the result to be verified on the graph and chart format.
| Data exploration and relationships – Clustering in RapidMiner (one page) |
Here, a model is created on the Rapid Miner with the help of the given data of the restaurant. The model creation utilizes the Random Forest and the neural nets classifiers. The below diagram depicts the creation model for these two classifiers.
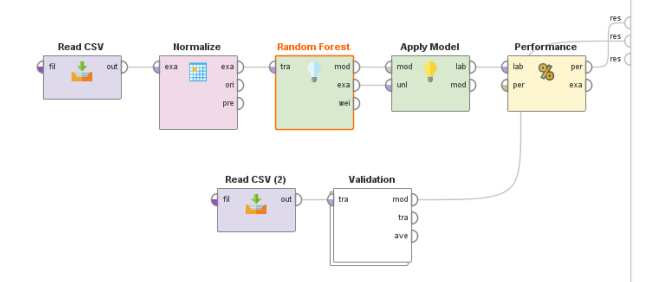
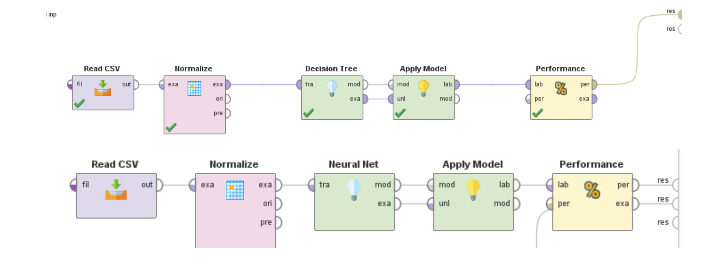
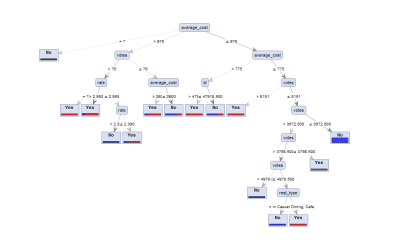
For creating a model, initially it is required to include the read CSV operator for reading the data of the restaurant. Next, it is required to replace the missing values with the help of the normalize operator, as it might impact the results of our model. Then, with the help of the Random Forest and KNN operator define the label attributes to be predicted. Further, the required qualities are selected for including it to predict the attributes. The following figure depicts the decision tree.
During the creation of the model, the accuracy parameters are selected on the classifier, ad it is utilized for measuring the predictor’s accuracy and their performance. The other parameters and depth and set as default. For proving an effective model for Zomato restaurant data BFA, the Random Forest is utilized. The below figure illustrates the output of the neural nets algorithm.
| Data exploration and clean up – Anomalies in RapidMiner (one page) |
Here, the relationships and the data transformation will be discovered that is given in the restaurant data, with the help of Rapid Miner. A correlation matrix must be created for identifying the connection of the data and its transformation. The operators like Filter Examples, Read CSV, Set roles, correlation matrix and select attributes are used to create the correlation matrix. The below figure depicts the relationships.
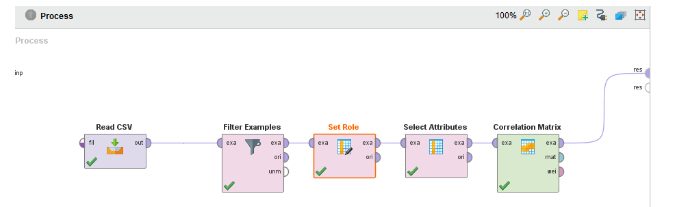
The label attributes are required to create the correlation matrix that is specified in the case study such as the book table. Then, the recommendations are evaluated. The following figure illustrates the correlation matrix.
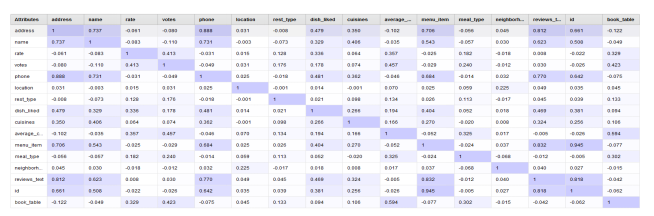
The below represented chart is utilized for displaying all the attributes that are arranged based on their correlations.
| Create a Model(s) in RapidMiner (two pages / page 1) |
Here, a model is created on the Rapid Miner with the help of the given data of the restaurant. The model creation utilizes the Random Forest and the neural nets classifiers. The below diagram depicts the creation model for these two classifiers.
For creating a model, initially it is required to include the read CSV operator for reading the data of the restaurant. Next, it is required to replace the missing values with the help of the normalize operator, as it might impact the results of our model. Then, with the help of the Random Forest and KNN operator define the label attributes to be predicted. Further, the required qualities are selected for including it to predict the attributes. The following figure depicts the decision tree.
During the creation of the model, the accuracy parameters are selected on the classifier, ad it is utilized for measuring the predictor’s accuracy and their performance. The other parameters and depth and set as default. For proving an effective model for Zomato restaurant data BFA, the Random Forest is utilized. The below figure illustrates the output.
| Create a Model(s) in RapidMiner (two pages / page 2) |
The model that is created utilizes a couple of classifiers called the Random Forest classifier and the Neural nets classifier, where the Random Forest makes use of four criteria; where the accuracy criteria is selected for providing the model’s accurate prediction, which is later utilized for determining the two services, hence it gives effective outcomes for the customers of the BFA company. This is then applied on the Example sets with the numerical attributes, however just on the nominal attributes. It delivers the outputs like the Random Forest and the example set.
Both, standard deviation and excellent performance estimation of the created model is possible with the cross-validation performance, which senses the data. The above mentioned performance of the restaurant data and its estimation is impacted by overfitting. The Kaggle website is used for analyzing the data preparation. The following figure depicts the created model’s deployment.
| Evaluate and Improve the Model(s) in RapidMiner (two pages / page 1) |
Here, the Rapid Miner based created model will be evaluated for improving it, with the help of a performance operator. This operator helps in providing effective results for the BFA Company. Moreover, this operator is utilized in the created mode, for evaluating the performance of the created model by giving Accuracy and Kappa values. Further, the performance operators even improvises the complete performance of the created models, which is illustrated in the following figure.
Additionally, the performance operator is utilized for improving and assessing the statistical performance evolution of the given restaurant data. Then, this operator also gives a list of performance criteria values related to the classification task such as Kappa and accuracy. The performance operator is mainly is utilized in the classification task, where it gives the input port exporters as labelled, for instance, it sets and delivers the performance vector as result. However, the performance vector is utilized for listing the performance criteria values for the given data such as Accuracy, Kappa etc. It states that the output depends on a couple of parameters namely the Accuracy attribute and Kappa attribute. The use of accuracy parameter is to show the prediction’s percentage, whereas the kappa parameter’s use is to measure the simple percentage of the right prediction calculation, which is represented in the following figure.
.
| Provide an Integrated Solution in RapidMiner (one page) |
Here, the Rapid miner based created model will be deployed with the help of a cross-validation operator. This operator helps in determining the statistical performance of the created model. Cross-validation comprises of a couple of sub-processes namely the Training Processes and the Testing Processes, and these processes are referred as the input port and the output port for delivering the output of the prediction model trained on the complete example set.
The model that is created utilizes a couple of classifiers called the Random Forest classifier and the Neural nets classifier, where the Random Forest makes use of four criteria; where the accuracy criteria is selected for providing the model’s accurate prediction, which is later utilized for determining the two services, hence it gives effective outcomes for the customers of the BFA company. This is then applied on the Example sets with the numerical attributes, however just on the nominal attributes. It delivers the outputs like the Random Forest and the example set.
Both, standard deviation and excellent performance estimation of the created model is possible with the cross-validation performance, which senses the data. The above mentioned performance of the restaurant data and its estimation is impacted by over fitting. The Kaggle website is used for analyzing the data preparation. The following figure depicts the created model’s deployment.
| Further Research and Extensions in RM (one page) |
Here, the given data will be researched and its extensions will be determined. The given data set of the restaurant comprises of various missing values, along with the inadequate attributes, thus in Rapid Miner such attributes are replaced and moved to the data exploration and preparation section. Later, a couple of main characteristics (i.e., book _ table and Order _ online) are used for determining and discovering the services such as Book a table and Online meal ordering, which are the expected results for Zomato restaurant and its customers depending on its restaurant reviews.
The Random Forest and Neural netsclassifiers are used for determining the expected results of the Zomato restaurant depending on the two services. On the other hand, these classifiers successfully give effective results for the development of Zomato restaurant’s data mining.
The use of Random Forest classifier helps to show the given data’s accuracy, and it clearly shows that BFA is interested in the two services and provides effective outcomes for the restaurant. And, this is determined with the help of the performance operator. For providing the data which shows the BFA is interested in the outcome of the two services, the Neural netsis also utilized, where it shows the highly effective outcomes for the Zomato restaurant. Next, it has even used the performance vector for determining the accuracy and kappa value, which is identified as 92.70% and 0.062, respectively.
Depending on the created classification models, it is utilized for providing effective results for the restaurant data. It even gives effective result i.e., book a table service and the online meal order service as the beneficial services for its customers. Such services tend to give effective outcomes for any restaurant, and it is identified by the Random Forest model. According to the results of the Random Forest model, 92.70% of accuracy is displayed and with a clear Random Forest diagram containing the two services which are compatible for Zomato restaurant, depending on its reviews. The created models are later evaluates and validates the booking table service, Zomato review, and the order online service. The performance and cross-validation models are viewed for checking the overall visualization of the create model. Here, the user has not conducted an independent research associated to data set analysis for determining whether our predictions could confirm or extend the results that were published previously.