- Introduction
- Background and context
Decision support is becoming more important in recruitment platforms to handle high levels of applications and ranking functions influence the surfaced candidate and role. In this context, the study of recommender systems [1] has discussed the ranking quality as one of the fundamental goals and comparing CV evidence and job requirements is the means of prioritizing matches. Recruitment is not the same as entertainment recommendation since errors may have an impact on economic opportunity, organisational performance and perceived fairness. This dissertation contextualizes CV driven job recommendation as a kind of information retrieval that compares relevance with a task where a CV representation well fits a job representation, and in which the use of methodological transparency is essential.
- CV data challenges
The input of CVs is challenging since it combines structured information with unstructured text accounts, and its length can drastically differ, and the ability can be indirectly explained through accomplishments instead of formalized titles. In the context of lexical overlap, the preceding research [2] has been observed to find that matching is compromised by synonymy, abbreviations and domain-specific phrasing particularly when projects and experience entail more richness than key words list. Practical implications are consequences of this. Applicants can also be given irrelevant advice and fail to get the right jobs, hiring organizations can also fail to get a talented candidate because of surface form incompatibility and platforms can also lose user confidence when ranking results seem out of sync. These drawbacks encourage the replacement of similarity based on keyword with representations that maintain meaning within the linguistic diversity and at the same time can be used to rank them in a scalable manner.
- Problem statement
The problem under evaluation is the enhancing effect of semantic representations on CV to job matching quality compared to lexical baselines under a controlled evaluation framework. Semantic similarity, the concept as described in [3], is proximity of meaning between the written CV text and the job-related text which is operationalized as similarity score that drives a ranked list of each query. Definitions of better performance: Retrieval measures are used to define better performance; these measures are precision at k, recall at k, mean reciprocal rank, mean average precision and NDCG. Since recruitment systems bring about issues of responsible use, the study only reports disparity indicators where the dataset allows meaningful grouping, and does not make claims that would require such attributes have protected ground truth, or downstream hiring outcome data.
- Research gap
The use of paired job postings, interaction, or labelled relevance judgments in most of the research in this area creates a research gap as such signals are not readily available in restricted datasets and other minor academic research. In the presence of only CV text, the analysis should be put in a new perspective by defining the competing approaches on an equal comparative task definition without exaggerating statements as stated in [4]. That gap is addressed in this dissertation through defining a proxy retrieval task, which is cross-method consistent, and recording the influence of preprocessing and section assembly decisions on the resulting rankings. The scope is also relative and analytical, and not a production placement or a forecaster of employment results.
- Aim and questions
The objective is to compare that the statement embeddings based on transformers are more useful in providing meaningful CV matching than those based on TF IDF and BM25 and they maintain reproducibility and nationally delimited claims. Goals define the result that will be achieved: Strong parsing of a JSON per row CV data, schema validation and cleaning that will put fields into a common type and minimize identifier leakage, section conscious assemblage of query and document texts, realization of TF IDF cosine similarity and BM25 scores as reference points, realization of an embedding based semantic scorer with cosine similarity, and examination on fixed train validation test splits with paired significance testing [5]. This is followed by three research questions, namely, whether embeddings are better at the proxy task than lexical baselines, whether the results are sensitive to the choice of preprocessing and assembly, and what risks of responsible use are visible with the available data.
- Contributions
Contributions are framed in the context of creating a design of evaluation and accountable reporting with limited data instead of promoting a new model. First, the dissertation offers a justifiable method of converting heterogeneous structured CV JSON into homogeneous representations that maintain the meaning of section and regulate noise due to sparse optional fields. Second, it provides a comparative benchmark, where lexical and embedding methods are evaluated under a single protocol, which allows one to make a clear statement regarding trade-offs between efficiency and semantic coverage. Third, it combines significance testing with conservative risk analysis in such a way that improvement will be inferred as measured effect in order to balance the choice of methods to be used with explainability and governance requirements in [6]. The evidence of these contributions can be seen in the artefacts of the pipeline and the results tables that show the centrally tendentious and variability results.
- Dissertation structure
Chapter 2 will review the recommenders in recruitment, the methods of CV representation, embedding strategies, and the measures of evaluation in order to inspire the design decisions. Chapter 3 will indicate the research philosophy, experimental strategy, threats to validity and ethics approach that limit claims and direct reporting. Chapter 4 will outline data provenance and observed schema and Chapter 5 will outline parsing choices, cleaning choices and section assembly choices. Chapter 6 will outline the definition of baseline and transformer methods and Chapter 7 will detail the implementation and testing evidence. Chapter 8 will provide results, statistical tests, Chapter 9 will present the findings in comparison with literature, Chapter 10 will provide the summarization of project management evidence, and Chapter 11 will conclude with answers, contributions, and future work.
2. Literature Review
2.1 Theoretical foundations
Recruitment matching can be formulated as a recommender problem where an object, e.g., vacancy or profile of a candidate, is ranked based on evidence of text and contextual traits. In the modern recommender taxonomy, content-based methods based on profile and item characteristics, collaborative filtering based on interaction histories, and hybrid methods based on both are distinguished, and the fact that non-accuracy constraints, including transparency, governance and operational risk usually influence reality deployments is highlighted. These framing facilitates thinking of the CV-to-job matching as a ranked retrieval mission where the goal is to put the most relevant opportunities on top of a shortlist as opposed to making one binary choice. In this theoretical perspective, lexical retrieval is a means of interpretation, and semantic learning of representation is regarded in the case of lexical overlap breakdown in synonymy and variable syntax. These underpinnings also encourage assessment by more than a single score, since recruitment environments demand justifiable data of the quality of ranking and prudent application [7].
2.2 Key empirical studies
Recent empirical recruitment recommender research has shown that the behavioral and contextual signals of large scale can be exploited by hiring platforms, as well as exposing limitations that are not normally manifested consumer recommendation. An example of a contextual learning method into job or candidate recommendation demonstrates how professional networks can utilize big-data scale cues to enhance ranking relevance in dynamically sensitive situations, without being overridden by time sensitivity and the scarcity of explicit feedback [8]. To elaborate on this line, explainable job-posting recommendation explains how knowledge graphs and entity-centric representations can be used to generate ranked outputs and post hoc explanations, implying that transparency capabilities can be integrated into the matching pipeline, and not added to it after ranking [9]. Resume parsing studies use sequence labelling and multi-task learning to operationalize CV representation in terms of information extraction, with the fields being structured, and searching the unstructured text with the aim of making the fields more usable downstream. Extraction accuracy and runtime are considered to be central goals as they indicate the pragmatic necessity to scale the parsing to a high degree of consistency prior to a matching system becoming consistent in its operation [10]. The focus on rapid and precise parsing turns up the point that it is possible to attain structured sectioning, yet it also refocuses on what has not been tested in cases where the downstream matching quality is not considered [11].
2.3 Critical comparison of literature
Across these studies, a general conflict appears between what is optimizable and what can be justified under real-life problems. When rich network signals are used to compute rankings, recruitment recommenders can be useful to rankings in situ, but reproducibility is hampered where standalone data of CVs are available. Accountability is enhanced by explainability work, which also may be based on the assumption of the presence of a network of related entities and curated graphs, which do not necessarily exist within a self-contained dataset. Parsing research enhances the trustworthiness of field extraction; however, extraction execution is not the same as matching execution, thus a well-parsed CV may still be ill matched as long as the representation and similarity element fail to preserve meaning. This inspires the attention towards the representation learning to the similarity scoring. An embedding based methodology that acquires consistent similarity ranking, shows that embedding geometry and training tasks impact on cosine similarity behaving as intended, which is of direct importance when embeddings are used as retrieval cues, and not as classification cues [12].
Studies are also characterized by evaluation choices that vary differences in the credibility of comparisons. Ranking measures are most often reported, although metric meaning is based on explicit assumptions of relevance, aggregation and interpretation, therefore conclusions may be undermined by reporting averages without justifying the implications of measurement by them. Advice regarding batch evaluation emphasizes that the form of metric choice must be appropriate to the decision structure of the task and comparisons must be based on a good definition of what constitutes a correct or useful ranking response [13]. Simultaneously, risk-oriented recommender studies demonstrate that evidence of accuracy is not enough in cases where deployment has an impact on the opportunity distribution. The perceived injustice of collaborative filtering constitutes an example of how unbalanced information and interaction feedback can be converted into systematic inequalities, which is an indication that evaluation must comprise at least descriptive checks when group signals are available [14]. A ranking method based on fairness also shows that both visibility and exposure are designable as design goals, which suggests that the recruitment-style recommendation should address such policy concerns as the distribution of attention among items or applicants [15].
2.4 Identification of research gap
The reviewed literature offers solid foundation, yet it has a gap that is relevant to the independent dissertation based on structured CV data. Recruitment recommenders are scalable and explainable, but tend to use interaction logs or knowledge graph resources that cannot be assured on a self-sourced CV data. Parsing research demonstrates that structured representations can be recovered, although it does not determine the behavior of competing matchers on the resultant structured texts at a controlled, similar protocol. Integrating research enhances the argument of semantic similarity but also cautions that embedding design options may corrupt similarity measurement which needs explicit benchmarking and not an assumption. Lastly, fairness and evaluation demonstrate that ranking metrics should be justified and that accountable reporting ought to realize the possibility of bias, but real-life fairness measurement is typically restricted by the unavailability of shielded qualities. Thus, there is still a thwart in end to end, reproducible benchmarking, linking structured preprocessing of the CV data, lexical baselines, transformer embeddings, and defendable evaluation in the presence of explicit data limitations.
2.5 Direct linkage to research questions
The literature review indicates that recommendation systems in recruitment are scalable and explainable but such evaluations are frequently associated with resources that might not be present in an isolated structured dataset of CVs including interaction logs and linked knowledge graphs [8]. Explainability approaches show that structured representations can assist in transparency, though it presupposes entity resource and downstream validation requirements that are not always replicated in independent research [9]. Resume parsing experiments indicate that structured CV fields can be reclaimed correctly and effectively, but does not determine the behavior of various matchers on the resultant structured texts on a more controlled and comparable benchmarking protocol [10]. Multi-task extraction makes it more robust, but does not address the question of representation decisions, like section assembly and missingness, on the consistency of downstream matching [11].
Concurrently, there has been an implication that embedding research shows that similarity behaviour is a factor of training goal and embedding geometry; that is, dense retrieval cannot be presumed to be better without empirical experimentation on the desired retrieval framing [12]. Assessment work also underscores the fact that prioritization of metrics will need a clear set of assumptions and justifiable interpretation and this is what drives a controlled retrieval protocol and cautious reporting as opposed to sweeping proclamations [13]. The research on fairness demonstrates that the results of the recommendation are prone to differences when there is imbalance in the data and the feedback, but CV datasets are frequently not guaranteed to have trustworthy protected features, and thus responsible reporting should be limited by quantifiable quantities [14]. These holes drive two research questions which can be managed in a Master time span and which are directly related to the limitations of the data set and the dissertation purpose.
RQ1: Do transformer-based sentence embeddings improve CV matching performance compared with lexical baselines, specifically term frequency-inverse document frequency (TF-IDF) and Best Matching 25 (BM25), under a controlled retrieval protocol? This question tests whether semantic similarity can bring quantifiable ranking benefits over term overlap with recruitment-type language, whilst acknowledging that embedding design may influence levels of similarity reliability [12].
RQ2: How do preprocessing and representation decisions, particularly section assembly and weighting, influence retrieval quality, and what responsible constraints follow from dataset limitations and limited fairness signals? This question addresses the documented disconnect between extraction-focused structuring and downstream matching validation, and it ensures that evaluation assumptions, fairness constraints, and reporting limits are explicitly stated rather than implied [13].
The research gap is directly covered by these questions because they compare the lexical and embedding methods on structured representations of the CV under a transparent evaluation protocol and limit the making of claims to what can be substantiated by the dataset.
3. Methodology
3.1 Philosophical approach
This study is based on a positivist philosophical approach in which the knowledge assertion is assessed based on observable and measurable evidence and validity of the results is determined based on the reproducibility of results under specified conditions. This position is suitable since the main activity in the dissertation is the quantitative benchmarking of retrieval algorithms based on the existing metrics of ranking to create the output that can be objectively compared and tested statistically. It would be less appropriate to adopt a more interpretivist position since the work does not attempt to interpret human experiences or meaning of recruitment, but to establish whether the algorithmic representations can modify measured retrieval behaviour with controlled inputs. The stance also constrains claims: the results are only considered evidence on the behaviour of the model when following the prescribed protocol and not causal effects in hiring decisions or human decision-making.
3.2 Research design
The research design was a quantitative experimental benchmarking study since the essence of the core claims were assessed by determining the differences of retrieval performance as a controlled experimental study. The design had fixed task definitions, deterministic data partitions and uniform preprocessing between methods in such a way that any observed difference would be due to modelling and representation decisions and not procedural difference. The design did not intend to forecast the actual hiring results and position the system as a programmed hiring decision-maker. As an alternative, the inference unit was ranking quality within a specified assessment protocol, and results were viewed as performance evidence within the assumption of the dataset and the task.
The plan involved the combination of baseline benchmarking, comparative experimentation as well as ablation-like analysis to isolate the influence of representation options on corresponding quality. The benchmark compared lexical methods and transformer embeddings over a common scoring and ranking interface, and was able to change results based on difference in representation, not due to inconsistent pipelines [16]. Two levels of unit of analysis were determined, full CV representation and section level text representations, to allow varied control over the inclusion of which evidence sources. The evaluation employed a knowledgeable retrieval framing due to the lack of labelled CV –job relevance pairs, and ensured the same relevance assumptions across methods, which enabled method-to-method comparability and decreased interpretive ambiguity in reported performance [17]. The success was determined as constant or continuously increasing ranking measures of held-out test data with statistically defensible paired comparisons.
The choice of the methods was based on the need to reach a compromise between interpretability, semantic coverage and feasibility. TF-IDF and BM25 have excellent lexical grounds that indicate the presence or absence of semantic models adding value to term overlap. Cosine similarity is a uniform scoring procedure to sparse vectors and dense embeddings that can be employed as one ranking pipeline. Transformer sentence embeddings are selected based on the similarity of contextual representations, and pooling is an option of design as the representation of similarity may be influenced by pooling. Section weighting also exists as the CV fields have different levels of signal strength and density but is auditable and can analyze section errors. There is no need to emphasize that generative modelling is not the focus because it does not achieve the same goal of retrieval; there are no user interaction logs between the filters and collaborative filtering area is thus ruled out and since there are no the labelled relevance pairs, the learning-to-rank was not possible.
Internal validity is preserved by avoiding leakage and doing the same preprocessing of methods. The deterministic train, validation, and test splits were used, and tuning is limited to validation data to prevent the optimistic bias, which is in line with the empirical control principles [16]. The alignment of the selected metrics to the decision task; multiple measures of ranking are reported due to the fact that various metrics reflect various outcomes facing the user, and the confidence interval of the measures should be reported where possible. In the review of Joseph and Ravana [17], the reliability of the IR evaluation depends on the judgement design, and therefore the restrictions of the relevance definition of proxies are mentioned verbally. CV only data and domain shift are the limits of external validity and will be tested in the future with job descriptions. Configuration, seeds, and run metadata are recorded; reproducibility of platforms is known to be relevant as identified by Isdahl and Gundersen [18] which drives the need to document this information.
A limitation of this design is that it uses a proxy retrieval task in the absence of job descriptions and human relevance judgements, which reduces external validity for real recruitment settings. Despite this, the proxy framing remains suitable for benchmarking because every method is evaluated under identical relevance assumptions and identical inputs, enabling defensible comparative conclusions. Alternatives such as learning-to-rank were considered, but they were not suitable here because they require labelled relevance pairs or defensible weak supervision, which the dataset did not provide.
3.3 Dataset description
The dataset comprised two files: the dataset documentation (PDF) and CV-Dataset.csv, where each row stored one structured CV record. The data constituted secondary data because it was collected outside the dissertation work and then reused for controlled experimentation. The documentation indicated collection via an online form under an anonymization and consent claim, making it suitable for methodological benchmarking where direct participant contact was unnecessary. The dataset was selected because it provided rich, multi-section CV evidence in a consistent schema, supporting section-aware representation and controlled ablations that would be difficult with unstructured resumes alone. The ingestion run parsed 132 records without error, while the documentation indicated a different entry count; the dissertation therefore reported the discrepancy explicitly and treated the observed CSV as the authoritative experimental input. This source choice aligned with established practice in resume-focused studies that treat CVs as heterogeneous documents whose structure must be normalized before downstream modelling and matching can be assessed reliably [19].
The CSV contained a single JSON column, where each row stored one JSON object representing a CV record. The highest-level keys that are witnessed are Objective | Summary, Education, Experience, Projects, Skills, Others, Extracurricular Activities and Certifications. The extracurricular activities appear in most records and Certifications appears in few records and the other certification content is visible in the others. The others are a flexible container with varying Section labels and descriptions hence; downstream processing cannot assume an existing taxonomy. All fields are therefore maintained in a data dictionary that stores the expected keys, allowed types and missingness designs which are compatible with structured schema analysis techniques [20]. Important presence rates are established to facilitate profiling, auditing and reporting.
Field typing was made normal to minimize variations prior to modelling. Objective| Summary and Skills were represented as a list of strings, and Education, Experience, Projects, and Extracurricular Activities will be lists of objects that have defined subfields. The descriptions of experiences are then normalized to lists of strings and Others is represented as a list of nested section objects with raw and canonicalised section labels. Where values were represented as strings, were empty or were lacking, cleaning converted the values to target types or removed them to enhance data quality [21]. Records which would not pass parsing in JSON or validation in key would be declared as outliers in order to maintain integrity, none of which failed the observed run.
The biggest weakness is that the dataset consists of CVs with no matched job posting or relevance labels, and therefore there is no way to directly measure the end-to-end job recommendation effectiveness. Constructed strategies are established to facilitate comparative benchmarking, such as synthetic job description assembled out of sections, skill-Query retrieval against experience and project text and clustering based assessment of semantic grouping. The skill-query retrieval framing was utilized in the notebook due to the ability to offer consistent queries and objective ranking goal within the existing schema. The design can be used to allow comparisons that are controlled and limit claims on something other than hiring impact, namely semantic matching performance.
A limitation is the relatively small sample size and the reliance on secondary data claims (for example, anonymisation and consent are treated as stated in the documentation rather than independently verified), which constrains generalisation; however, the dataset remains suitable for controlled benchmarking because it provides consistent multi-section CV structure needed for reproducible representation experiments.
3.4 Data preparation
Parsing implemented a strict “one JSON object per row” policy, rejecting non-dictionary outputs to prevent silent schema drift. Robustness was addressed through defensive failure handling: any row that failed JSON decoding would be quarantined with its row identifier recorded, and excluded from modelling to avoid corrupting downstream evaluation. This approach followed broader data quality guidance that emphasizes explicit detection and handling of missingness, malformed inputs, and inconsistent field structure rather than implicit correction that obscures provenance [22]. In addition, systematic cleaning surveys emphasize that repeatable pipelines should make validation rules explicit and treat error handling as part of data quality management, not as an afterthought [23]. Schema checks verified the presence of required top-level keys and enforced allowed types per field, while nested checks ensured list-of-object sections contained valid dictionaries with expected subfields. Key normalization handled casing variance and minor spelling variants where observed, and missing optional keys were defaulted to empty lists to prevent brittle downstream branching during feature assembly and scoring [24].
Removing empty strings, dummy objects and blank entries in all sections helped clean up noise and make sure that the length effects were not artificial. Normalization destroyed repetitions of whitespace and normalized spaces between punctuations and capitalization, but retained significant tokens as acronyms and the names of tools. Duplicate removal was used when the same strings were found within a section several times, and a check on record-level duplication was established to avoid the replication of the dataset accidentally. The URLs and identifier-like tokens were obscured to minimize the leakage of personal information, and also to make it impossible to retrieve the file using distinctive links. Labels of the sections under Other were canonicalised using forms that have been normalized so as to facilitate uniform grouping. The default stopword removal was not used due to the fact that domain words may have similarities with stopwords and thus the baseline retained them and used weighting. The tokenization of TF-IDF and BM25 was defined differently [24]. A limitation is that embeddings were used in inference mode without domain fine-tuning, so performance reflects general semantic capability rather than recruitment-specific adaptation; this choice remained appropriate because the dataset did not provide labels required for supervised tuning.
Section assembly transformed the cleaned structured fields into consistent textual representations while preserving semantic boundaries between CV components. Assembly rules applied uniform separators and stable ordering so that differences in downstream performance reflected modelling choices rather than inconsistent formatting effects, consistent with reproducible text pipeline practice where representation must be controlled before method comparison [22]. Experience entries were concatenated using role, organisation, duration, and bullet descriptions, while education and projects were formatted as name–description pairs, with masked link placeholders retained to preserve record structure without exposing identifiers. Skills were joined into a compact query-style representation aligned to the chosen proxy retrieval framing, while “Others” was mapped into section-label and description pairs to retain auxiliary information as optional evidence. Truncation and diagnostic chunking were applied to manage long records and to support later error analysis without changing the evaluation goal. Optional keys remained safely representable because missing sections were standardized to empty forms during parsing and cleaning, preserving downstream stability [24].
Weighting logic was created to indicate that CV parts do not match one another equally. It was supported in three weighting options. Equal weights formed a baseline and sections are treated equally. To facilitate the close alignment of recruitment practice where demonstrated work predominates over signals, heuristic weights were used to put more weight on experience and projects than on auxiliary content. Tuned weights were considered to be validation-based modifications that are maximizing ranking measures and maintaining interpretability. Section-level similarities were weighted with a convex sum such that the total scores in the records were similar. Normalization employed per-query scaling in order to regulate the variance in the event of an empty or sparse section. Sensitivity analysis used weights over a limited range to experiment the robustness and to avoid a domineering effect of one section over the other using artefacts of preprocessing [25].
The structured features were regarded as optional additions to the core signals. Skill counts, the number of experience items and a proxy of an education level were calculated to facilitate diagnostic analysis and possible hybrid scoring. Features were only added when they enhanced performance on validation data, and when they did not add proxy bias because of some correlation in identifiers. The feature distributions were also checked to see the heavy tails that might prevail in the linear models. To avoid information leakage, standardization was done using z-scores calculated on the training set. In case features worsened the fairness indicators or stability, then they were eliminated and the rationale was recorded [22].
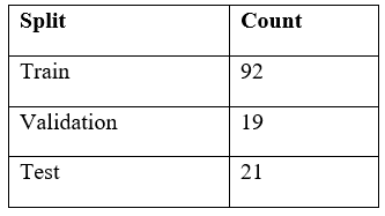
Reproducibility was ensured by randomly partitioning used a deterministic random seed into train, validation and test partitions. Stratification was not presupposed due to the absence of the labels of classes, but indicators of section completeness were observed to make sure that the splits did not accumulate a few records in a single partition. The train split fit takes parameters of tuners and validations, the validation split chosen thresholds and weights, and final metrics were only reported in the test split. Any form of preprocessing which predicts statistics, e.g., feature scaling, was trained on training data and applied on subsequent splits. The robustness check that was defined as cross-validation was when the dataset size gave unstable estimates and the primary reporting involved the fixed split protocol to ensure comparability [22].
3.5 Model architecture
The anchoring performance was done using the baseline suite that employed TF-IDF and BM25. TF-IDF employed a fixed vocabulary limit, one or two grams and standard term weighting followed by cosine similarity to get query document scores. BM25 used lowercased parametrized alpha numeric tokenization (k1, b) during scoring. An irreducible floor was defined by a random ranker that helped to check sanity. It was done by using inputs of the same section text such that the only differences were in how it was scored by the different methods. To compare efficiency, runtime was timed on each method and timings were taken according to IR benchmarking advice [26].
Selection of transformers was based on semantic accuracy, computability and CV language appropriateness. Embedding was the only option in the form of inference as the supervised fine-tuning labels were not available. A limitation is that embeddings were used in inference mode without domain fine-tuning, so performance reflects general semantic capability rather than recruitment-specific adaptation; this choice remained appropriate because the dataset did not provide labels required for supervised tuning. Group mean differences were determined when there were labels of groups.
Both queries and documents were turned into embeddings, and batching was used to regulate the memory as well as stabilise throughput. Mean pooling and CLS pooling were considered an alternative aggregation since pooling may alter the evidence, which dominates a representation. Long inputs were truncated to accommodate model constraints and section assembly done to minimize redundant tokens to be encoded. The evaluation runs made use of caching such that repeated scoring did not re-embed, and the notebook showed embeddings statistics, as opposed to artefact files being written.
The score of both sparse TF-IDF vectors and dense embeddings under a single ranking interface was based on cosine similarity. In the rare cases where thresholding was necessary with any of the auxiliary classification-style checks, validation data were used to select thresholds to prevent test-set tuning bias.
A limitation of the cosine similarity is that it does not capture term dependence, and can be non-discriminatory to subtly semantic queries with the query being short and sparse in a query which is typical in skills-only queries. It was still appropriate in this case since the objective of the dissertation was controlled comparison with a unified scoring function that would be used in both sparse and dense representations. Alternatives like Euclidean distance were also not applied as they are sensitive to the magnitude of the vectors and are prone to length related bias when documents differ significantly.
Candidate generation brute force scored the evaluation subset to maintain comparisons being precise and to prevent approximation artefacts. The output of ranking of all queries was a top k list of similarity scores, allowing consistent evaluation of MAP and NDCG. The deterministic breaking of ties was done by index order such that repeated executions gave the same rankings. The evaluation activity used each query as the retrieval of the relevant document and this method was useful in controlled benchmarking in case external relevance labels were not available. Explainability outputs were applied as section and method score breakdowns such that the analysis could demonstrate the aspects of a CV that evoked retrieval. This design is based on semantic ranking practice [28] in which the quality and interpretability are both assessed. In case scaling is required, approximate indexing will be considered without definition changes of metrics in the future.
3.6 Evaluation metrics
The evaluation was framed as a ranked retrieval task since recruitment-style matching usually yields a shortlist and not an acceptance or the rejection response. Quality ranking was thus done based on complementary metrics that reflect early-rank accuracy and shortlist coverage. Mean reciprocal rank (MRR), evaluating the speed with which the first relevant document was found, and normalized discounted cumulative gain (NDCG at k), evaluating rank sensitive utility at fixed cutoffs, were used to rank the list of candidate documents on each query. Precision at k (P@k) and recall at k (R@k) were calculated at k in the set of integers, {1, 3, 5, 10} in order to achieve the reporting of shortlist behaviour in practical depths of screening, with increasing cutoffs associated with increased pools of candidates and limits on operational shortlisting. Mean and standard deviation in queries were indicated because they are summary statistics and show variability instead of using one aggregate score [17].
Since the proxy retrieval protocol entailed definition of a single relevant document per query, interpretation of metrics was explicitly done. At single-relevant conditions, the precision at k is mechanical, as at some rate there is no more than one relevant item that could be found in the top k rank, and thus P@k was more a measure of rank placement than a measure of multi-hitting. The recall at k just acted like an indicator of a hit on the same assumption in the sense that recalling the one and only relevant item anywhere in the top k results in complete recall. This limitation was addressed as a design quality of the dataset and task framing and it was reported in an attempt to avoid over-interpretation of the absolute metrics magnitudes as hiring precision. The analysis thus focused on likening differences between strategies in conditions of equal relevance criteria as opposed to external validity of recruitment effectiveness. Accordingly, conclusions are drawn from relative differences between methods under the same protocol rather than from the absolute magnitude of P@k and R@k as indicators of hiring precision.
The comparison between the methods was performed statistically since paired tests were applied because the results of the queries yielded matched metric values in all methods, and the difficulty was controlled within the query. Per-query distributions were tested with significance testing with paired t -test where assumptions were reasonable and Wilcoxon signed rank test as a non-parametric alternative, and a summary of the effect size of paired differences was given via Cohen d on the per-query deltas. When several comparisons were being compared, Bonferonni correction was performed to reduce the risk of false discovery through repeated testing [16]. Besides effectiveness, the evaluation also noted the runtime per stage to aid the interpretation of compute-awareness as feasibility and responsiveness are also operational constraints in recruitment systems.
3.7 Experimental setup
Implementation was delivered as a single, linear-execution Jupyter notebook which consumed the CSV data, unwrapped the JSON records, purified and normalized field format, assembled section-conscious textual forms, and ran both the baseline and transformer scoring with a common ranking application. The notebook generated ranking metric evaluation tables, statistical tests results, and diagnostic summary tables that allowed tracing preprocessing decision-making to the provided results. Through this structure, implementation was aligned with the lifecycle-oriented practice of pipeline, with configuration, artefacts, and decision points being expressed and auditable as opposed to being implied in ad hoc experimentation [29]. Deterministic splitting, shared preprocessing functions and a strict top-to-bottom execution convention were used to control known risks of notebooks like hidden state, out-of-order execution and environment drift [30]. Pipeline defects were also considered a major reliability risk in the testing and reporting design as failures in an evaluation and data wiring are common causes of failure in models [31]. Traceability was also ensured by associating intermediate outputs with distinctly marked stages and recording the rationale behind a transformation and the stage output in order to be verifiable again [32].
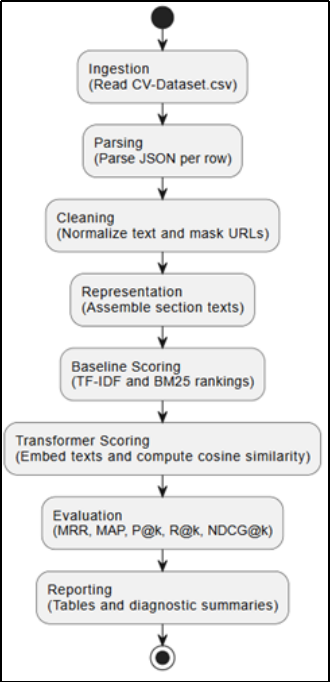
Figure 1 shows the processing steps which were carried out in the order in which they were carried out in the notebook so that the results would be reproducible. At every step, the intermediate representations generated were reused by subsequent steps, which minimized the ambiguity in the process of backtracking an outcome back to preprocessing and scoring decisions.
The execution engine was Python, and frames of data manipulation were performed using pandas and NumPy, and TF-IDF and cosine similarity were performed using scikit-learn. SciPy had assisted paired statistical testing and sentence-transformers inferred embedding inference to support the semantic method. The notebook was meant to be working on CPU with the ability to utilize the GPU whenever possible to add speed. The aspect of reproducibility was addressed with the help of fixed random seed, deterministic splitting and shared preprocessing functions across methods. Hidden state and variation in the sequencing of cells are known risks, and therefore, linear execution and explicit recomputation were used to minimize drift [30].
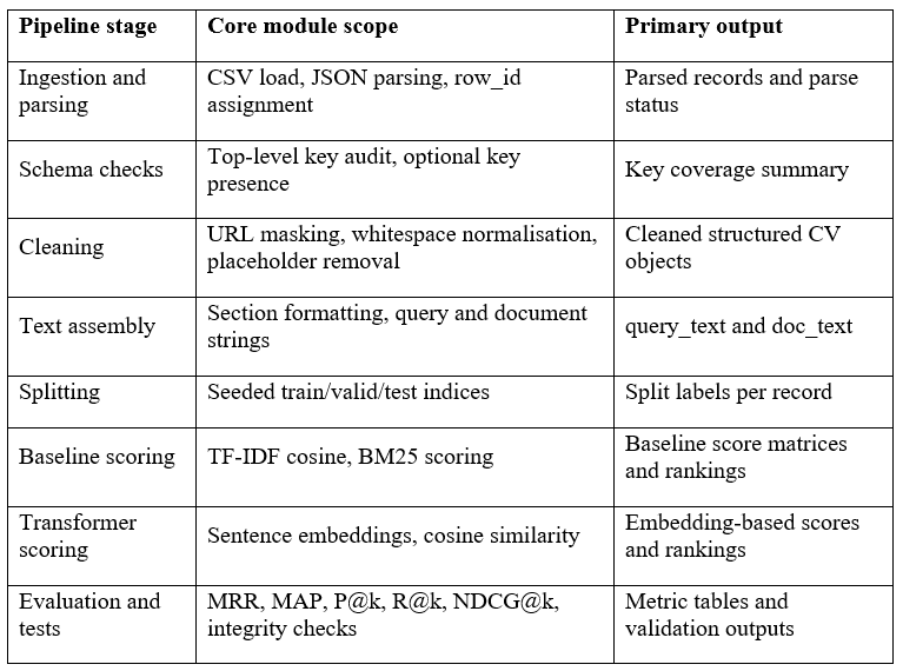
Table 1 describes the pipeline steps implemented and the precise products of each step, which aids in tracking the record of the raw records to the evaluation outcomes. The mapping also gives a clear delineation of the module’s boundaries, which diminishes the chances of concealed notebook condition or un-documented modifications towards the reported performance.
Table 1.End-to-end notebook pipeline
No supervised model training was performed since relevance labels were not availed, and thus the transformer component was run in inference mode on a pretrained sentence embedding model. Fine tuning was left as subsequent work which would involve relevance judgements or a justifiable weak supervision policy which is consistent with the ranking goal. In case training is possible, the design will record learning rate, epochs, batch size, and maximum sequence length alongside validation metrics, and the early stopping and checkpointing will choose one best model by the validation performance. This plan is in line with the sustainable pipeline practices which focus more on configuration capture and lifecycle governance [29].
Runtime design put similar execution between methods. TF-IDF, BM25 and transformer scoring were run on the same evaluation set thus the differences indicate modelling preferences but not candidate sets. The embedding computation has been batch-controlled and the caching of document embeddings has avoided recomputations of document embeddings within a run. The time was put down according to each stage to compare the cost per query and to determine the bottlenecks. The current dataset was used with exact scoring to eliminate approximation bias, and the extension to vector indexing was specified to enable the extension of scalability in case of increasing dataset size. Missing fields had the value of an empty string, and empty queries had the value of a zero vector to allow continuity of the pipeline.
Testing combined unit, integration, and evaluation validation because each addressed a distinct failure mode that could undermine the credibility of results. Unit tests targeted deterministic functions that are prone to silent corruption, including JSON parsing, schema validation, URL masking, and cleaning rules, since small preprocessing defects can materially change downstream ranking outputs without obvious runtime failure. Integration tests then validated end-to-end reproducibility by confirming that fixed seeds produced identical splits, identical intermediate representations, and stable rankings across repeated runs under the same configuration, which controlled common notebook execution risks such as state leakage and accidental partial reruns [30]. Evaluation tests verified metric correctness on constructed toy cases and ensured that any threshold or weight selection remained restricted to validation data, preventing optimistic bias from test-set tuning. Alternatives such as extensive property-based testing or fully automated CI pipelines were considered but were not prioritized due to project scope; instead, the design focused on coverage of the most consequential pipeline risks that commonly drive ML system failure, including mis-implementation of evaluation and inconsistent preprocessing [31]. This approach maintained a defensible balance between rigor and feasibility while supporting reproducible artefact delivery [29].
1.1 Ethical considerations
Data ethical compliance was in compliance with the UoY ethics review process, which included a process of confirming the minimal-risk handling, data governance decisions were documented, and approved storage and access controls were adhered to. Due to the possibility of indirect identifiers in CV text, preprocessing involves systematic de-identification, e.g. URL masking and avoidance of raw-text disclosure in outputs, in realization that anonymization minimizes risk, but is not irreversible in all circumstances of adversarial attack [33].
The dissertation also aligned conduct with professional expectations under recognized computing ethics frameworks (including ACM and IEEE principles) and treated GDPR as the governing basis for lawful processing, minimisation, and purpose limitation when handling personal data. Fairness checks were treated as monitoring, not proof of discrimination, and were only reported where group signals were explicitly present and sufficiently supported by sample size. To strengthen accountability, lineage and configuration metadata were recorded to enable traceability of results and responsible auditability of artefacts across the pipeline lifecycle [34]. Reproducibility was treated as part of research integrity, acknowledging known risks from platform and environment variability [18].
The danger of privacy does not disappear since the text may contain links to the third party, usernames, or the name of the organisation, thus the URLs are disguised and the results do not contain any raw personal data. Preprocessing deletes or replaces identifiers and minimizes and de-identifies any qualitative examples. Aggregate statistics and metric tables are used to limit logging of the sensitive text. Storage will only be done under controlled local storage and packaging of artefacts will not contain any redundant raw outputs but maintenance of reproducibility under approved controls of access.
Fairness assessment was treated as conditional monitoring, not as a definitive evaluation of discrimination, because protected-attribute labels were not systematically available and proxy grouping can introduce misleading inferences. The pipeline therefore avoided using protected attributes as model inputs and only computed group comparisons where a group signal was explicitly present in the data and met minimum size requirements. When feasible, the method reported a demographic-parity-style difference computed as the spread between group mean metric values, alongside an opportunity-style comparison using recall at k, while also reporting sample sizes to contextualize uncertainty. This design positioned fairness reporting as part of reliable evaluation practice where risk indicators are disclosed cautiously and tied to measurement limits rather than overstated as causal findings [35]. Where group support was absent or insufficient, the dissertation omitted fairness statistics entirely rather than presenting unstable estimates, and mitigation actions were framed as documentation, sensitivity analysis, and governance controls instead of undisclosed tuning.
1.2 Justification of methodological decisions
Methodological decisions were chosen to ensure that the dissertation could answer the two research questions completely under the constraints of available data and within a reproducible evaluation protocol. The dataset lacked job descriptions and labelled CV–job relevance pairs, so the study adopted a proxy retrieval design that preserved comparability across methods by fixing the relevance assumption and keeping the pipeline constant [17]. Skills text was treated as the query representation because it approximated requirement-like descriptors, while the remaining sections formed the evidence-bearing document representation, enabling controlled benchmarking of semantic versus lexical matching without implying real hiring outcomes. This framing directly supported RQ1 by enabling a controlled comparison of transformer embeddings against TF-IDF and BM25, and it supported RQ2 by making section assembly and weighting explicit levers whose effects could be isolated.
The reason lexical baselines were held was due to the fact that they offer transparent and auditable points of reference and determine whether semantic approaches can add value over and above term overlap. TF-IDF had a sparse-vector benchmark that was sensitive to term weighting whereas BM25 had a better lexical baseline by virtue of term-frequency saturation plus document-length normalization, the latter being important when the CV sections are very disparate. Cosine similarity has been chosen as a unified scoring operation since it is used equally on sparse TF-IDF vectors and dense transformer embeddings with the result that ranking outputs can differ mainly due to representation and not due to incompatible scoring principles. Transformer embeddings were optimized on inference mode since inference would not need relevance labels, and the pretrained sentence embedding model would be feasible in the system but still would test whether the contextual representations affected the retrieval behaviour. The pooling and truncation were considered controlled representation choices since they have the ability to alter the evidence that prevails in the embedding, which is why they were reported as methodological degrees of freedom, and not as secret implementation information.
Several alternatives were discussed but not taken due to the fact they will undermine validity under the conditions as observed. It was also ruled out collaboration-based filters and hybrid based on interaction-based recommenders since no interaction logs were available and as such any model would have been based on assumptions that were not backed by the data. The reason why learning-to-rank was not sought was that it needs labelled relevance pairs or weak supervision that is defensible; bringing in synthetic labels without strong reasons would be tantamount to circular testing and exaggeration of performance results. Generative modelling was also not given priority as the objective of the research was ranked on par with performance when scored similarly, rather than text generation or decision explanation and the addition of generation would introduce more issues to evaluation that could not be confirmed by the provided data. These exclusions enhanced construct validity because it streamlined the methods to that which could be defensibly evaluated as opposed to methods which might be technically implemented [16].
Reproducibility and research integrity were treated as part of methodological justification, not as an implementation afterthought. Deterministic splits, fixed random seeds, shared preprocessing functions, and strict notebook execution order were used to reduce hidden state and procedural variation, acknowledging known risks in reproducibility across ML platforms and environments [18]. Traceability was strengthened through explicit configuration capture and artefact-oriented outputs to enable verification and re-execution, consistent with lineage and governance recommendations for trustworthy ML pipelines [34]. Ethical safeguards were justified by the nature of CV text as potentially identifying data; de-identification through URL masking and cautious reporting reduced privacy risk while recognizing that anonymization is not absolute [33]. Fairness checks were constrained to cases where group signals were explicitly present and sufficiently sized, and omission of fairness statistics under weak support was treated as a responsible methodological choice rather than as evidence of fairness [35].
2. Results and Findings
2.1 Data profile
The resulting dataset generated 132 viable CV records and there were no errors in parsing all records with JSON (Table 2, Table 3). The documentation was different in the count of entries; thus, the count of entries that was observed determined the sample to use in practice in the modelling. All records had required top level fields and so could not be eliminated during preprocessing (Table 4).
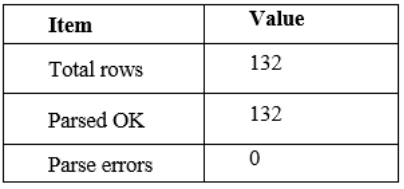
Table 3.Observed top-level JSON keys
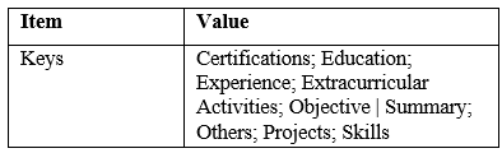
Table 4.Key coverage audit
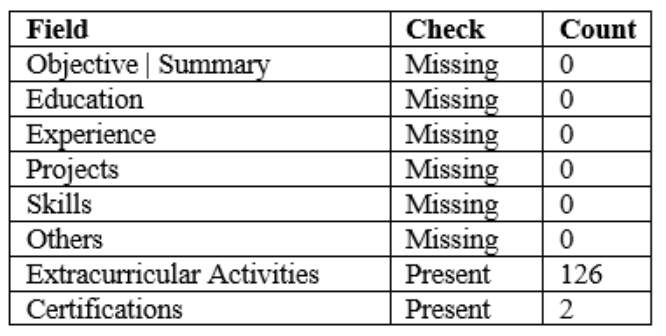
Non-obligatory sections were few, as Extracurricular Activities was found in 126 records at ingestion and 51 records at cleaning, and Certifications in only two records (Table 5). Skills based query generated three blank queries, whereas document texts were entire throughout the test set (Table 6). The deterministic split was with 92 records in training, 19 in validation and 21 in test (Table 7).
Table 5.Optional field non-empty after cleaning

Table 6.Text assembly emptiness.
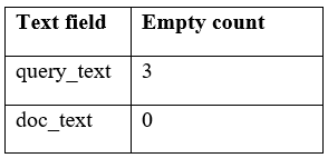
Table 7.Train, validation, test split counts
1.1 Baseline results
Baseline performance was evaluated on the 21-record test split using the self-match retrieval task. TF-IDF achieved higher MAP and MRR than BM25, with 0.561657 versus 0.502765, and both methods showed high dispersion across queries (Table 8). Early retrieval quality remained moderate, since recall at 1 was 0.428571 for TF-IDF and 0.333333 for BM25 (Table 9), while recall at 3 reached 0.619048 for both baselines (Table 10). Precision followed from the one relevant document framing, so precision at 1 equaled recall at 1 and precision at 3 fell below 0.21 for both baselines (Table 11). These patterns indicate that lexical overlap often located the matching document, but it was not consistently ranked first.
Table 8.MAP and MRR summary on test split
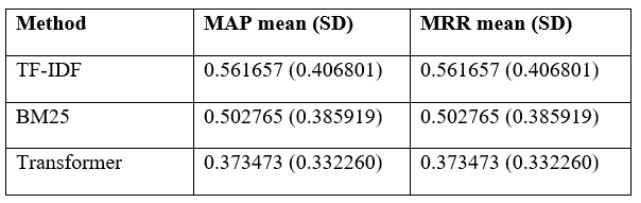
Table 9.NDCG summary on test split
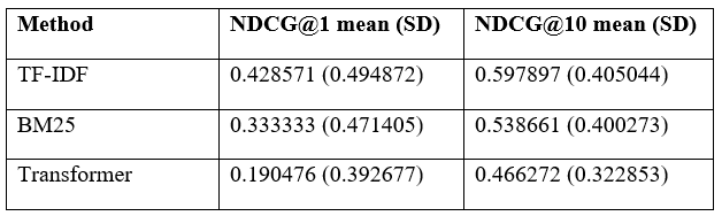
Table 10.Recall at k on test split (k = 1, 3).
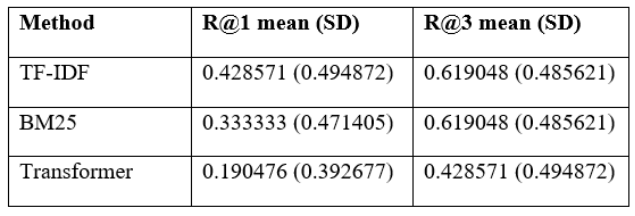
Table 11.Precision at k on test split (k = 1, 3)
1.1 Model results
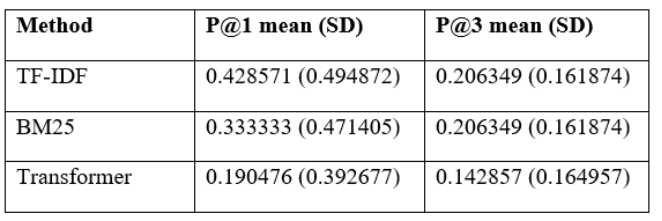
Transformer embeddings were tested in query and document texts; thus, variations are in representation and not candidate selection. In the first place, quality was not the top priority, as the values of NDCG at 1 are 0.190476 (TF-IDF) and 0.333333 (BM25), which are lower than both baselines. Large cutoffs recovered more relevant items, with recall at 10 increasing to 0.809524 and overtaking TF-IDF but approaching BM25 respectively (Table 12). The profile shows that there are a later recall of the similar document and a weaker early ranking regarding the selected proxy relevance. Accuracy on larger cutoffs remained low across methods because each query had exactly one relevant document, so the precision values primarily reflected how quickly that single match appeared in the ranked list rather than multi-relevant retrieval performance.
Table 12.Recall at k on test split (k = 5, 10).
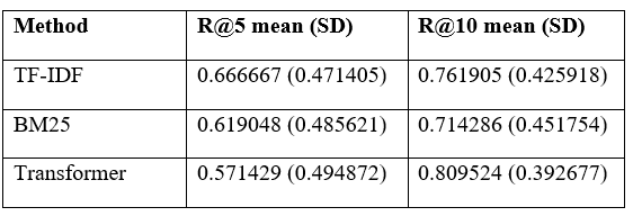
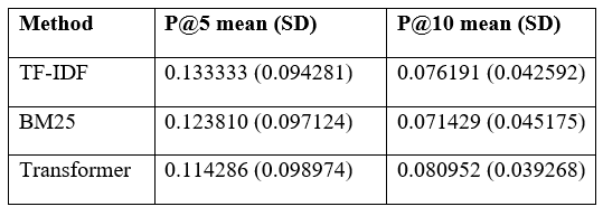
Table 13 reports that the transformer approach achieved P@5 = 0.114286 (SD = 0.098974) and P@10 = 0.080952 (SD = 0.039268), compared with TF-IDF at P@5 = 0.133333 (SD = 0.094281) and P@10 = 0.076191 (SD = 0.042592), and BM25 at P@5 = 0.123810 (SD = 0.097124) and P@10 = 0.071429 (SD = 0.045175). These values indicate that the transformer method retrieved the correct match within the top 10 slightly more often than both lexical baselines, while TF-IDF and BM25 placed the correct match marginally more frequently within the top 5. This pattern is consistent with higher-cutoff recall improvements, suggesting that semantic similarity helped recover matches that were missed by lexical overlap but did not consistently prioritise them at the very top ranks. The reported precision results reflect a single configuration using the default embedding pooling and the fixed section assembly, so they should be interpreted as a baseline semantic reference rather than an optimized transformer variant.
Table 13.Precision at k on test split (k = 5, 10).
1.1 Significance tests
Paired significance testing was used to compare the values of per query MRR to identify whether gaps in the methods were similar across identical queries. Paired t-test signified negative difference in transformer and TF-IDF and adjusted p-value of Bonferonni was 0.021700, which signified stable reduction in MRR (Table 14). The Wilcoxon signed-rank test gave p = 0.033971 of the same comparison whereas transformer versus BM25 was not significant (Table 15). The d of Cohen between transformer and TF-IDF and transformer and BM25 was -0.612874 and -0.368202, respectively, proving the negative relationship (Table 16). These findings dismissed H0 in TF-IDF and supported H0 in BM25. Only to this evaluation setting was the conclusion applied.
Table 14.Paired t-test on MRR (Bonferroni-adjusted p-values).
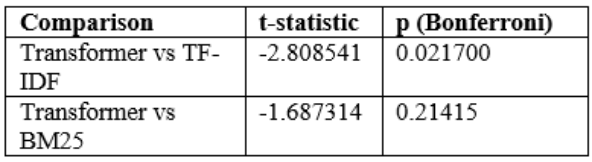
Table 15.Wilcoxon signed-rank test on MRR
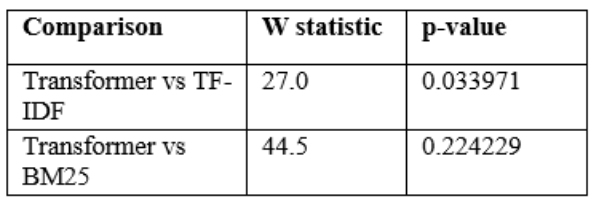
Table 16.Effect size on MRR (Cohen’s d, paired).

1.1 Error analysis
The analysis of errors was done on the effects of input sparsity and section structure on rankings. Very sparse CVs made poor queries where the Skills field was blank or excessively short, which made it less discriminative and more dependent on incidental overlap. Long narrative records augment truncation danger to the transformer encoder, as pertinent proof can be found late in experience histories or comprehensive description of a project. The introduction of noisy auxiliary sections brought general terms which were not role-specific, and at times these texts overshadowed similarity in cases where core ones were brief. We also saw skill list dominance since generic tool lists have the ability to match a large number of documents and decrease the early rank accuracy. These modes are what led to methods finding the correct document in the top 10 and not at the top.
According to case inspection, the lexical baselines did not perform well when synonyms were used in the same form, i.e., paraphrase, abbreviations, or domain specific words, and the transformer method failed when query used was generic and did not scope to a specific role. Section contribution review: Projects and experience were found to have more discriminative evidence than education on most records, but were missing, distributing power to auxiliary text. Some of the insights on mitigation that can be drawn based on these patterns are using query fallbacks on missing skills, filtering or down-weighting noisy auxiliary parts, and chunking long documents prior to encoding to limit the loss on truncations. These reforms aim at prioritizing stability without modifying the definition of evaluation. They favor having the coverage of documents per section to understand failures in replication and review
1.2 Fairness results
The concept of fairness monitoring was based on group labels derived based on auxiliary fields and had a threshold on the minimum group size to report. None of the groups met the threshold on the assessed split, and thus, group sums were blank and demographic difference of parity on MRR undefined (Table 17). This finding indicates that the data are not favorable to group comparisons lacking weak proxies or manual labelling and thus fairness outputs were regarded as availability checks as opposed to manifestations of parity. Passed integrity tests, which proved valid split labels and complete document text fields, and which attests confidence in metric computation (Table 18). When group labels are available, then disparities will be reported in size, uncertainty and mitigation advice to be used when making decisions. The future fairness analysis should be done with more information on the protected attributes with authorized governance.
Table 17.Fairness monitoring outcome.

Table 18.Integrity test output.

1. Discussion
1.1 Critical interpretation of findings
The comparison concerned semantic matching of job recommendation quality in case CVs were presented in the form of section-text. TF-IDF performed the best ranking in the early ranking that was done under the self-match retrieval task and BM25 was the second best. The embedding method of transformers decreased MAP, MRR, and NDCG at rank one thus the corresponding CV was less frequently ranked first. Transformer method, however, recalled the correct CV more frequently in the top ten, which made the recall higher at ten. These results addressed the major effectiveness question and they elucidated that token evidence in this dataset was used to do early short listing. The comparison question on the representation was also informed by the pattern.
The results also helped in understanding the reason behind selectivity of improvements as opposed to uniformity. All the methods were affected by query sparsity since three of the records contained blank skill queries and there was greater ambiguity in skill inventories among the candidates using generic inventories. Embedding model was trained without fine-tuning on the task, therefore there was no customization of the representation space to the proxy task and it probably overemphasized general semantic similarity. This discrepancy is aligned with the requirements to align embedding goals to similarity ranking tasks in contrastive pipelines of learning [36]. The trade-off hence was strength against intricacy and it emphasized the significance of query design. Embeddings also took a higher compute demand. This was the reason that semantic recall gains were not always converted into top-rank accuracy in the present setting.
1.2 Direct comparison with literature
Previous studies on person-job fit usually represent a variety of profile fields and interaction, which leads one to believe that recruitment matching is driven by systematic evidence and not a token list. Multi-field architecture learns skill, experience, and education in combination make signals of to be suited in case job descriptions and supervision are present [37]. The current assessment was different since there were no job ads and relevancy were not labelled and thus self-match proxy was adopted to maintain comparability between techniques. Even in such an environment, lexical overlap between skill queries and experience text can be a very predictive feature, and that is why TF-IDF and BM25 performed so well even when they are simple. Outcomes were therefore influenced by the proxy framing.
The knowledge-graph recommendation area demonstrates a complementary direction, which has the potential to enhance interpretability with the help of explicit links between users, items and extracted entities. Knowledge graph-based job recommendation systems can reduce sensitivity to noise in phrasing, based on similarity to structured concepts, as well as explanation templates [38]. The existing pipeline used the raw section text, and thus the similarity could be affected by the auxiliary fields in case core sections were very sparse. The common knowledge-graph learning perspective also highlights that the quality of the recommendations is related to the connection of the representations between the tasks and the evidence, which prompts the incorporation of entity-based constraints in the future [39]. This would be a direction that would support traceable explanations.
1.3 Theoretical implications
The results support a task-specific perspective of matching recruitment where ranking behaviour is a result of the interaction between representation choice and structure of evidence. In this experiment, query-based skills convergence narrowed signal into sparse lexical tokens, so lexical retrieval was stronger on early-rank placement whereas the embedding method distributed power more towards larger cutoffs through retrieving paraphrased competencies more frequently. This trend suggests that semantic improvement cannot be assumed as a homogenous anticipation, since it relies on the assessment of first-position shortlisting or subsequent coverage of shortlists, and operationalization of relevance. It also facilitates modelling recruitment recommendation as a stagewise retrieval issue, in which transparency, auditability and controlled generalization belong to the conceptual framework, and are not extra conditions.
1.4 Practical implications
A plausible platform design would therefore maintain lexical retrieval as the first-stage candidate generator due to its rapidity, interpretability and being well sensitive to queries involving skill inventories, and use semantic embeddings as re-ranking step with a smaller set of candidates on which higher cutoffs operationally worthwhile and further compute is affordable. The architecture minimizes the danger of semantic over-generalization and still supports competency paraphrases and also allows monitors to be carefully monitored once deployed, such as the ability to detect drift and recalibrate policy on demand. Explainability artefacts are capable of supporting governance through stakeholders being able to challenge rankings and identify spurious signals, and section-level contribution breakdowns are a lightweight transparency mechanism [40]. The tool must be operationalized as decision support and needs to be overridden and appealed by human actions as well as the tool needs to keep secured configuration and data lineage logs to facilitate auditing and safe change control [41].
2. Project Management
2.1 Milestone plan
The project delivery was controlled with the help of the output-based milestones which were synchronized with the assessment artefacts and supervisor review points. This proposal was turned in on 17 November 2025 and the plan went in the process of dataset parsing, cleaning and schema normalization, baseline completion, transformer evaluation and the generation of results table.
Table 19.Milestone deliverables and evidence
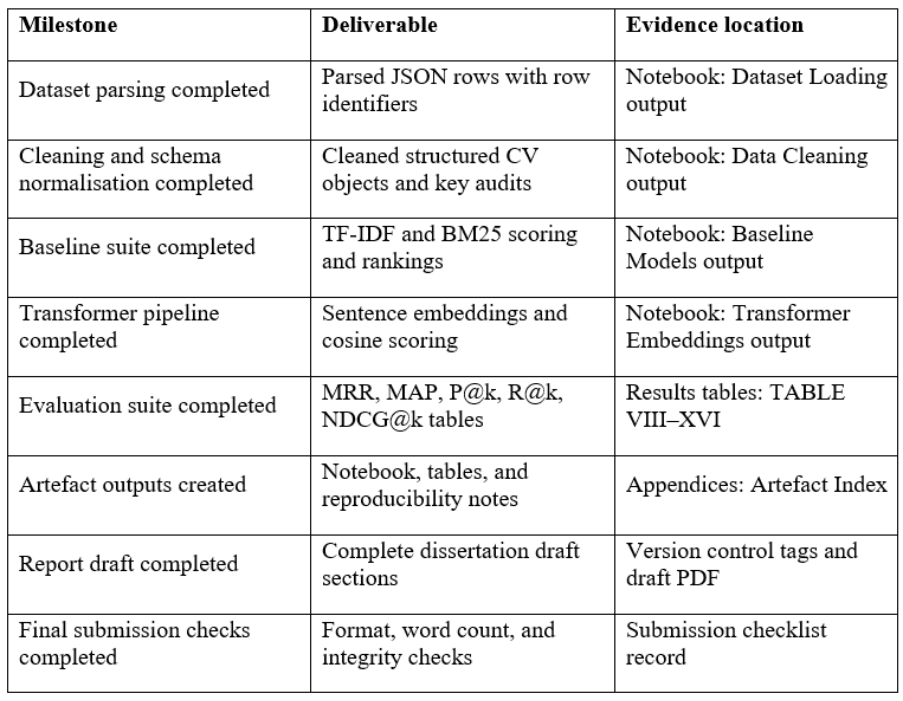
Every one of these milestones generated verifiable best practices, such as notebook cells, metric tables, and appendix items and each output was mapped to a place where it can be viewed and checked. The milestone set is consolidated in table 19 and each milestone is connected with its concrete deliverable and evidence location which facilitates the traceability and minimizes ambiguity when reviewing it. The practice conforms to the MLOps management practice of considering deliverables, documentation, and governance as lifecycle [42].
Every one of these milestones generated verifiable best practices, such as notebook cells, metric tables, and appendix items and each output was mapped to a place where it can be viewed and checked. The milestone set is consolidated in table 19 and each milestone is connected with its concrete deliverable and evidence location which facilitates the traceability and minimizes ambiguity when reviewing it. The practice conforms to the MLOps management practice of considering deliverables, documentation, and governance as lifecycle [42].
1.1 Dependency map
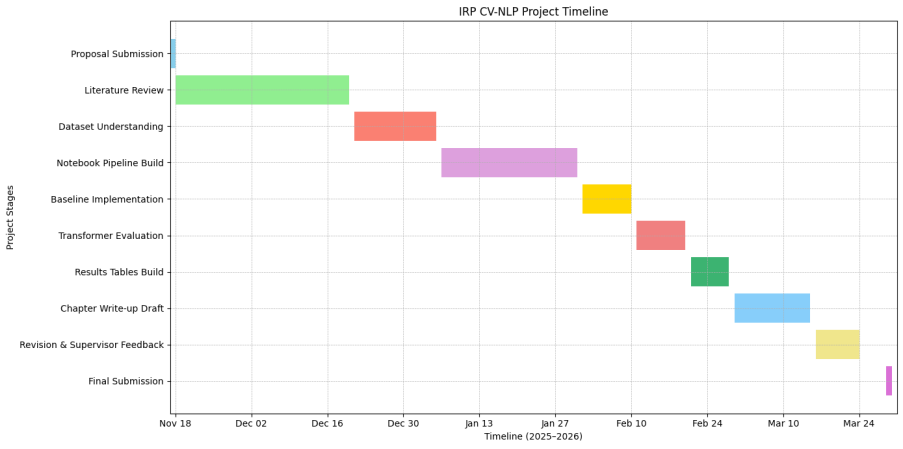
Dependencies were managed by enforcing a critical path where reliable data preparation preceded all modelling and evaluation tasks. Baseline scoring was completed before transformer evaluation to ensure performance comparisons were available even under compute constraints. Results tables depended on stable metrics and completed integrity checks, while chapter drafting depended on verified tables. Parallel work was possible between literature synthesis and notebook refinement, yet the evaluation stage remained gated by data readiness. Figure 2 visualizes the planned schedule from proposal submission through final submission and it highlights the revision window for supervisor feedback.
1.1 Rist log
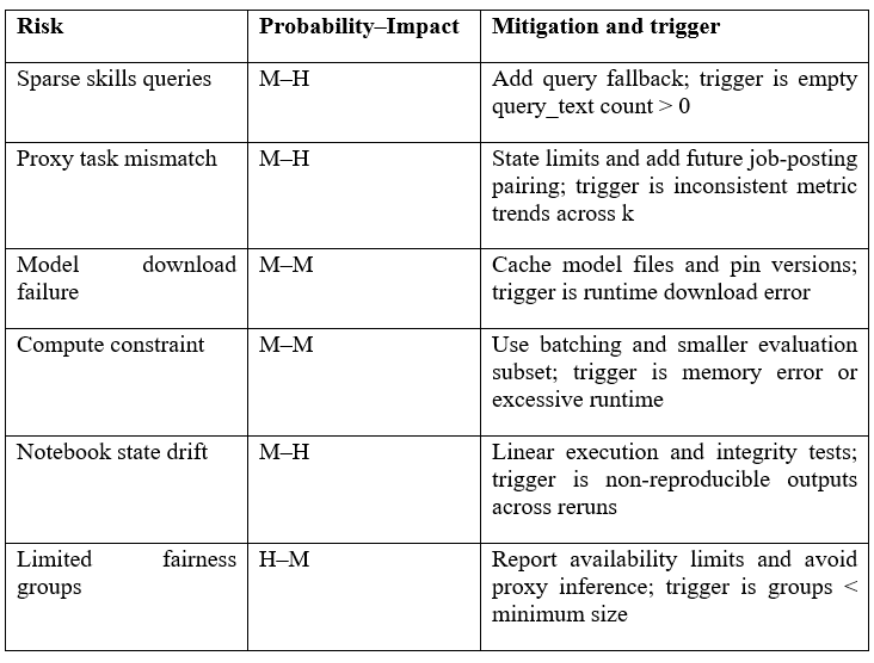
The risk management utilized a small register that monitored the occurrence of probability, impact, mitigation and action trigger. Table 20 provides a summary of the most probable risks that would have influenced the outcomes, which are skills query sparsity, proxy task mismatch, model download failures, compute limits, and notebook state drift. Every risk was tracked using observable parameters variable to the number of empty queries, irregular measurements between reruns, and runtime errors. Documented fallback mitigation, deterministic execution mitigation, caching, and conservative reporting, which is consistent with the real-world advice on risk management of a software project [43].
Table 20.Risk register summary
1.2 Resource plan
Compute was budgeted to run on CPU-only, and optional use of GPU to make embeddings faster should it be available. Submission was controlled by organized local directories and versioned artefact packages by storage. Notebook and table changes were tracked using version control, and documentations of reproducibility were made of the configuration and execution order. Freezing a baseline-only pathway on contingency planning (in case of transformer inference) and scheduling time in advance to format and check compliance was included.
1. Conclusion
1.1 Research questions and hypothesis
RQ1 asked whether transformer sentence embeddings improved CV matching compared with TF-IDF and BM25 under the controlled self-match retrieval protocol. On the held-out test split, the transformer strategy failed to be better than the lexical baselines on initial-rank effectiveness. TF-IDF achieved MAP and MRR of 0.561657, BM25 achieved 0.502765, and the transformer achieved 0.373473, showing weaker rank placement for the semantic method in this evaluation setting (Table 8). TThis trend was in line with the top-rank gain, where NDCG@1 for the transformer was 0.190476 compared with 0.428571 for TF-IDF, indicating fewer correct first-position placements (Table 9). The statistical evidence supported retaining the null for improvement because the transformer reduced per-query MRR against TF-IDF with a Bonferroni-adjusted p-value of 0.021700 (Table 14) and a moderate negative paired effect size of -0.612874 (Table 16). The findings did not hence support the hypothesis of improvement under RQ1 in the task framing that was adopted.
RQ2 asked how preprocessing and representation decisions affected retrieval quality and what responsible constraints followed from the dataset limits. The trade-off noticed was that the transformer was more likely to put the correct document in larger cutoffs, but it was more likely to put it at later in the ranked list. Recall at 10 for the transformer was 0.809524 compared with 0.761905 for TF-IDF, showing improved discovery within top-10 even when early-rank accuracy was lower (Table 12). This measure was consistent with the methodological decision to utilize short skill inventories as queries with longer evidence portions, which was designed to have maximum overlap of exact tokens at smaller ranks but permit semantics to add at larger cutoffs. Since just one transformer case was studied in this run, section weighting and pooling variants were not tested in this run and therefore, claims on representational sensitivity were confined to the implemented assembly only.
Preprocessing effects were observable as constraints on what the evaluation could reliably measure. Section assembly generated three empty skill queries that brought unavoidable ranking noise to the records, and diluted any method in retrieving the self-match document (Table 6). Cleaning showed also that optional evidence was small and patchy, 51 non-empty extracurricular sections and 1 non-empty certification field on normalization, and this reduced the practical effect of auxiliary fields in similarity scoring (Table 5). Group disparity could not be reported by fairness monitoring since there was no inferred group that reached the minimum size threshold, therefore the non-reported differences did not mean fairness and had to be treated as a data limitation (Table 17). Being constrained this way, future work will need job descriptions and relevance judgements to find out whether the same trade-offs can be true within realistic hiring-oriented targets.
1.2 Summary of contributions
The project gave a replicable artefact that consumes CV artefact, validates schema, cleanses text and builds section representations and runs a base line and embedding scoring on a fixed split. It produced a results package of the overall results in MAP, MRR, NDCG, precision and recall at k, paired tests and effect sizes. The cleaning design obfuscated the URLs and normalized the nested fields to the stable type that did not contain the silent error in the process of the vectorization. The basement and transformers input were the same so as to keep them comparable and also to audit the effects of approach. The debugging and profiling processes have been stored in section-level contents and numbers. The practice of the machine-learning applications in engineering is oriented to the traceability of data, codes, and results and the presented pipeline satisfied this need by having deterministic splits, integrity checks, and structured outputs.
The contribution to the practice is a definite reference point of the era when the lexical foundations dominate over a semantic approach of a skills-query paradigm, to be applied in safer methods decision making in recruitment tools. The existing resume appraisal systems tend to emphasize automated grading as opposed to the controlled retrieval comparison that carries with it statistical testing [44]. The dissertation provides an evaluation protocol and the evidence of significance that can be adopted to justify the arguments of difference in methods. It describes the measures that are most important regarding the quality of shortlists. The paper also adds to recommendation research since it shows how query design modifies the focus of ranking besides being consistent to the findings that systems are more effective when the attention is given to the most relevant ones [45]. The operational recommendation settings also presuppose explainability.
1.3 Limitations
Generalization was constrained by the dataset and the evaluation framing. The data was in the form of CVs alone, not job descriptions, relevance judgements or placements as observed, and therefore effectiveness was evaluated using a constructed retrieval task as opposed to end-to-end hiring. Due to the small size and stylistic heterogeneity of the sample, the given metrics should be considered evidence on comparative behaviour on observed records, rather than on performance on the population level. Disciplined execution order, version pinning and environment capture were also needed to provide replication because platform and tooling drift can occur even with fixed seeds and splits. Moreover, the demands in the labour markets vary with time, hence conclusions were limited to the frozen time of the project and not a dynamic scenario of recruitment [46].
The ranking patterns were influenced by the constraints of the method based on the study objective of testing whether semantic representations enhance matching as compared to lexical baseline. Transformer encoders were necessary to truncate, and thus late evidence in long experience histories might have been missed, which likely helped to weaken top-rank placement and the lower MRR of the embedding method than TF-IDF and BM25. Lexical baselines were able to process all the text and thus take advantage of any overlap in exact terms that may have taken place anywhere in a document. The proxy relevance design only allowed one relevant document to be returned in response to a query, and this mechanically reduced precision in large cutoffs, and implied that P@k only reflected rank position and not realistic hiring accuracy. There were also few fairness reporting since no inferred group received the minimum size threshold, and therefore, not indicating disparity estimates was not a demonstration of fairness.
1.4 Future research directions
The methodological limitation that predetermined the results should be addressed first in the future work. The existing analysis was based on a self-match proxy where a single relevant document is available on any query, thus the inclusion of labelled relevance pairs would allow optimization of ranking goals through supervision instead of indirectly through the rank placement. Under these labels, supervised learning-to-rank may be used to directly optimize the quality of shortlists, and also to determine whether the perceived trade-off in transformer placement, which is less strong initially but stronger globally, remains under a target aligned loss [47]. Two-stage design can then be considered where lexical search gives out candidates and a neural model re-orders them, which might enhance accuracy of early-rank without compromising interpretability of the candidate list [48]. Further explanation should also be enhanced over section-score reporting by embracing structured rationale outputs that can be audited and limited to suitable evidence surfaces [49]. These extensions would involve pre-registered ablations and split discipline restrictions to prevent leakage.
Data extensions should be designed to remove the CV-only limitation while keeping the pipeline reproducible. The inclusion of job descriptions would allow the possibility of a person-job fit assessment and would be able to analyze errors in a role and seniority-based manner, not just with proxy similarity by itself. The sampling must be done intentionally with several job families and experience levels in order to minimize representational skew and the gathering of fairness attributes should only be done under clear ethics endorsement to ensure that disparity analysis switches away to availability checking to statistically prudent subgroup reporting. Since previous discoveries were not able to be compared with fairness because they did not have adequate group sizes, future datasets are supposed to be governed with documentation of attribute provenance, consent and retention thresholds. Clear monitoring and auditing processes, such as drift reviews and reproducibility instructions, should then be embedded in the artefact package, which is in line with engineering recommendations with regard to reliable ML systems [50].
Bibliography
- N. D. Almalis, G. A. Tsihrintzis and N. Karagiannis, “A content based approach for recommending personnel for job positions,” IISA 2014, The 5th International Conference on Information, Intelligence, Systems and Applications, Chania, Greece, 2014, pp. 45-49, doi: 10.1109/IISA.2014.6878720.
- N. D. Almalis, G. A. Tsihrintzis, N. Karagiannis and A. D. Strati, “FoDRA — A new content-based job recommendation algorithm for job seeking and recruiting,” 2015 6th International Conference on Information, Intelligence, Systems and Applications (IISA), Corfu, Greece, 2015, pp. 1-7, doi: 10.1109/IISA.2015.7388018.
- R. Thali, S. Mayekar, S. More, S. Barhate and S. Selvan, “Survey on Job Recommendation Systems using Machine Learning,” 2023 International Conference on Innovative Data Communication Technologies and Application (ICIDCA), Uttarakhand, India, 2023, pp. 453-457, doi: 10.1109/ICIDCA56705.2023.10100122.
- N. R, S. S. L, S. K, and S. L, “Smart Job-Seeking assistant and web scraping,” International Journal of Computer Engineering in Research Trends, vol. 12, no. 11, pp. 1–15, Nov. 2025, doi: 10.22362/ijcert/2025/v12/i11/v12i11011.
- Y. -C. Chou and H. -Y. Yu, “Based on the application of AI technology in resume analysis and job recommendation,” 2020 IEEE International Conference on Computational Electromagnetics (ICCEM), Singapore, 2020, pp. 291-296, doi: 10.1109/ICCEM47450.2020.9219491.
- Y. Zhang, B. Liu, J. Qian, J. Qin, X. Zhang and X. Jiang, “An Explainable Person-Job Fit Model Incorporating Structured Information,” 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 2021, pp. 3571-3579, doi: 10.1109/BigData52589.2021.9672057.
- Y. Li, K. Liu, R. Satapathy, S. Wang and E. Cambria, “Recent Developments in Recommender Systems: A Survey [Review Article],” in IEEE Computational Intelligence Magazine, vol. 19, no. 2, pp. 78-95, May 2024, doi: 10.1109/MCI.2024.3363984.
- W. Chen et al., “Tree-Based Contextual Learning for Online Job or Candidate Recommendation With Big Data Support in Professional Social Networks,” in IEEE Access, vol. 6, pp. 77725-77739, 2018, doi: 10.1109/ACCESS.2018.2883953.
- C. Upadhyay, H. Abu-Rasheed, C. Weber and M. Fathi, “Explainable Job-Posting Recommendations Using Knowledge Graphs and Named Entity Recognition,” 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 2021, pp. 3291-3296, doi: 10.1109/SMC52423.2021.9658757.
- X. Li, H. Shu, Y. Zhai and Z. Lin, “A Method for Resume Information Extraction Using BERT-BiLSTM-CRF,” 2021 IEEE 21st International Conference on Communication Technology (ICCT), Tianjin, China, 2021, pp. 1437-1442, doi: 10.1109/ICCT52962.2021.9657937.
- Y. Liang, Z. Lin, X. Shi and H. Ma, “Fast and Accurate Resume Parsing Method Based on Multi-Task Learning,” 2023 International Conference on Asian Language Processing (IALP), Singapore, Singapore, 2023, pp. 84-89, doi: 10.1109/IALP61005.2023.10337278.
- X. Huang et al., “CoSENT: Consistent Sentence Embedding via Similarity Ranking,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2800-2813, 2024, doi: 10.1109/TASLP.2024.3402087.
- A. Moffat, “Batch Evaluation Metrics in Information Retrieval: Measures, Scales, and Meaning,” in IEEE Access, vol. 10, pp. 105564-105577, 2022, doi: 10.1109/ACCESS.2022.3211668.
- Á. González, F. Ortega, D. Pérez-López and S. Alonso, “Bias and Unfairness of Collaborative Filtering Based Recommender Systems in MovieLens Dataset,” in IEEE Access, vol. 10, pp. 68429-68439, 2022, doi: 10.1109/ACCESS.2022.3186719.
- Q. Zhu, Q. Sun, Z. Li and S. Wang, “FARM: A Fairness-Aware Recommendation Method for High Visibility and Low Visibility Mobile APPs,” in IEEE Access, vol. 8, pp. 122747-122756, 2020, doi: 10.1109/ACCESS.2020.3007617.
- B. A. Kitchenham et al., “Preliminary guidelines for empirical research in software engineering,” in IEEE Transactions on Software Engineering, vol. 28, no. 8, pp. 721-734, Aug. 2002, doi: 10.1109/TSE.2002.1027796.
- M. H. Joseph and S. D. Ravana, “Reliable Information Retrieval Systems Performance Evaluation: A Review,” in IEEE Access, vol. 12, pp. 51740-51751, 2024, doi: 10.1109/ACCESS.2024.3377239.
- R. Isdahl and O. E. Gundersen, “Out-of-the-Box Reproducibility: A Survey of Machine Learning Platforms,” 2019 15th International Conference on eScience (eScience), San Diego, CA, USA, 2019, pp. 86-95, doi: 10.1109/eScience.2019.00017.
- M. Srivastava and P. Greaney, “Resume Parsing Across Multiple Job Domains Using a BERT-Based NER Model,” 2023 31st Irish Conference on Artificial Intelligence and Cognitive Science (AICS), Letterkenny, Ireland, 2023, pp. 1-4, doi: 10.1109/AICS60730.2023.10470917.
- Z. Zhang and T. Lv, “JSVE: JSON Schema Variant Extraction Based on Clustering and Formal Concept Analysis,” in IEEE Access, vol. 13, pp. 145517-145527, 2025, doi: 10.1109/ACCESS.2025.3599650.
- C. Cichy and S. Rass, “An Overview of Data Quality Frameworks,” in IEEE Access, vol. 7, pp. 24634-24648, 2019, doi: 10.1109/ACCESS.2019.2899751.
- Z. Liu and A. Zhang, “Sampling for Big Data Profiling: A Survey,” in IEEE Access, vol. 8, pp. 72713-72726, 2020, doi: 10.1109/ACCESS.2020.2988120.
- X. Wang and C. Wang, “Time Series Data Cleaning: A Survey,” in IEEE Access, vol. 8, pp. 1866-1881, 2020, doi: 10.1109/ACCESS.2019.2962152.
- R. Nasfi, G. de Tré and A. Bronselaer, “Improving Data Cleaning by Learning From Unstructured Textual Data,” in IEEE Access, vol. 13, pp. 36470-36491, 2025, doi: 10.1109/ACCESS.2025.3543953.
- F. A. Satti et al., “Unsupervised Semantic Mapping for Healthcare Data Storage Schema,” in IEEE Access, vol. 9, pp. 107267-107278, 2021, doi: 10.1109/ACCESS.2021.3100686.
- K. A. Hambarde and H. Proença, “Information Retrieval: Recent Advances and Beyond,” in IEEE Access, vol. 11, pp. 76581-76604, 2023, doi: 10.1109/ACCESS.2023.3295776.
- H. Cho, D. Choi and H. Lee, “Re-Ranking System with BERT for Biomedical Concept Normalization,” in IEEE Access, vol. 9, pp. 121253-121262, 2021, doi: 10.1109/ACCESS.2021.3108445.
- C. Limongelli, M. Lombardi, A. Marani and D. Taibi, “A Semantic Approach to Ranking Techniques: Improving Web Page Searches for Educational Purposes,” in IEEE Access, vol. 10, pp. 68885-68896, 2022, doi: 10.1109/ACCESS.2022.3186356.
- D. A. Tamburri, “Sustainable MLOps: Trends and Challenges,” 2020 22nd International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 2020, pp. 17-23, doi: 10.1109/SYNASC51798.2020.00015.
- J. F. Pimentel, L. Murta, V. Braganholo and J. Freire, “A Large-Scale Study About Quality and Reproducibility of Jupyter Notebooks,” 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 2019, pp. 507-517, doi: 10.1109/MSR.2019.00077.
- S. Li†, J. Guo†, J. -G. Lou, M. Fan, T. Liu‡ and D. Zhang, “Testing Machine Learning Systems in Industry: An Empirical Study,” 2022 IEEE/ACM 44th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Pittsburgh, PA, USA, 2022, pp. 263-272, doi: 10.1145/3510457.3513036.
- T. Mondal, S. Barnett, A. Lal and J. Vedurada, “Cell2Doc: ML Pipeline for Generating Documentation in Computational Notebooks,” 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), Luxembourg, Luxembourg, 2023, pp. 384-396, doi: 10.1109/ASE56229.2023.00200.
- A. Majeed and S. Lee, “Anonymization Techniques for Privacy Preserving Data Publishing: A Comprehensive Survey,” in IEEE Access, vol. 9, pp. 8512-8545, 2021, doi: 10.1109/ACCESS.2020.3045700.
- M. Raatikainen, C. Souris, J. Remes and V. Stirbu, “Machine Learning Lineage for Trustworthy Machine Learning Systems: Information Framework for MLOps Pipelines,” in IEEE Software, vol. 42, no. 1, pp. 51-58, Jan.-Feb. 2025, doi: 10.1109/MS.2024.3414317.
- Z. Yang, J. Tang and H. Liu, “Cloud Information Retrieval: Model Description and Scheme Design,” in IEEE Access, vol. 6, pp. 15420-15430, 2018, doi: 10.1109/ACCESS.2018.2797131.
- P. H. Le-Khac, G. Healy and A. F. Smeaton, “Contrastive Representation Learning: A Framework and Review,” in IEEE Access, vol. 8, pp. 193907-193934, 2020, doi: 10.1109/ACCESS.2020.3031549.
- M. He, D. Shen, T. Wang, H. Zhao, Z. Zhang and R. He, “Self-Attentional Multi-Field Features Representation and Interaction Learning for Person–Job Fit,” in IEEE Transactions on Computational Social Systems, vol. 10, no. 1, pp. 255-268, Feb. 2023, doi: 10.1109/TCSS.2021.3134458.
- H. Wang, Z. Gu and M. Gu, “Job Recommendation Algorithm Based on Knowledge Graph,” 2022 IEEE 8th International Conference on Computer and Communications (ICCC), Chengdu, China, 2022, pp. 2023-2027, doi: 10.1109/ICCC56324.2022.10065776.
- Q. Li, X. Tang, T. Wang, H. Yang and H. Song, “Unifying Task-Oriented Knowledge Graph Learning and Recommendation,” in IEEE Access, vol. 7, pp. 115816-115828, 2019, doi: 10.1109/ACCESS.2019.2932466.
- A. Adadi and M. Berrada, “Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI),” in IEEE Access, vol. 6, pp. 52138-52160, 2018, doi: 10.1109/ACCESS.2018.2870052.
- D. Protschky, L. Lämmermann, P. Hofmann and N. Urbach, “What Gets Measured Gets Improved: Monitoring Machine Learning Applications in Their Production Environments,” in IEEE Access, vol. 13, pp. 34518-34538, 2025, doi: 10.1109/ACCESS.2025.3534628.
- L. Faubel et al., “MLOps for Cyberphysical Production Systems: Challenges and Solutions,” in IEEE Software, vol. 42, no. 1, pp. 65-73, Jan.-Feb. 2025, doi: 10.1109/MS.2024.3441101.
- R. C. Williams, J. A. Walker and A. J. Dorofee, “Putting risk management into practice,” in IEEE Software, vol. 14, no. 3, pp. 75-82, May-June 1997, doi: 10.1109/52.589240.
- R. Pradeepa, A. C. Charumathi, R. Siva, S. I. Unais Sulthan and B. Vishnukumar, “Intelligent Resume Evaluation Tool Based on Machine Learning for Analysis And Career Advancement,” 2024 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, 2024, pp. 1-8, doi: 10.1109/ICERCS63125.2024.10895464.
- N. Pejić, Z. Radivojević and M. Cvetanović, “Helping Pull Request Reviewer Recommendation Systems to Focus,” in IEEE Access, vol. 11, pp. 71013-71025, 2023, doi: 10.1109/ACCESS.2023.3292056.
- S. Ashrafi, B. Majidi, E. Akhtarkavan and S. H. R. Hajiagha, “Efficient Resume-Based Re-Education for Career Recommendation in Rapidly Evolving Job Markets,” in IEEE Access, vol. 11, pp. 124350-124367, 2023, doi: 10.1109/ACCESS.2023.3329576.
- S. D. N. Silva, E. S. De Moura, P. P. Calado and A. S. Da Silva, “Effective Lightweight Learning-to-Rank Method Using Unified Term Impacts,” in IEEE Access, vol. 8, pp. 70420-70437, 2020, doi: 10.1109/ACCESS.2020.2986943.
- J. Yoon and L. Sael, “Document Re-Ranking With Evidential Neural Networks,” in IEEE Access, vol. 13, pp. 161964-161972, 2025, doi: 10.1109/ACCESS.2025.3609194.
- K. Kim, M. Sohn and J. Kim, “Cross-Domain Explainable Recommendation Using Graph Convolutional Networks and a Topic Model,” in IEEE Access, vol. 13, pp. 118310-118323, 2025, doi: 10.1109/ACCESS.2025.3581344.
- F. Khomh, B. Adams, J. Cheng, M. Fokaefs and G. Antoniol, “Software Engineering for Machine-Learning Applications: The Road Ahead,” in IEEE Software, vol. 35, no. 5, pp. 81-84, September/October 2018, doi: 10.1109/MS.2018.3571224.