Project Description
A report is represented which revolves around the prediction of specific crime categories. The provided data is Chicago crime data, which will be predicted and analyzed with the help of STATISTICA Text miner. This miner is STATISTICA Data Miner’s optional extension, which is perfect to translate the unstructured text data into valuable and meaningful, clusters of decision-making.
Therefore, the real-world data comprises of various forms, and there is guarantee to have an organized or easy to analyze data. Additionally, the data sources could be large. This is where the STATISTICA text miner helps to present the underlying information. It ensures optimization and data enhancing for such data.
Statistica Text Miner
STATISTICA Text Miner is mainly developed as a basic and open-architecture tool to ensure text mining the unstructured information. The text miner software is completely integrated into STATISTICA (“STATISTICA Text Miner”, 2020). It isn’t any stand-alone product that is developed by the vendor and linked with STATISTICA. The functionality of text mining is integrated in the workspace environment of STATISTICA Data Miner, STATISTICA Enterprise, or the application of custom STATISTICA.
As large portion of data in the data set is unstructured, the reliable help is provided by text mining to analyze the data patterns, which were missing earlier, for instance, when the feature analysis outlines crimes’ top predictor variables, it can even be beneficial for understanding the particular type of crimes. Therefore, instead of seeing crime as a large category, it is essential to view the particular crime types like theft, assault, and kidnapping. Hence, text mining permits the users to analyze unstructured data, then to produce the lift charts for every single crime types to have deeper understanding.
To perform STATISTICA text mining ensure that the following instructions are followed:
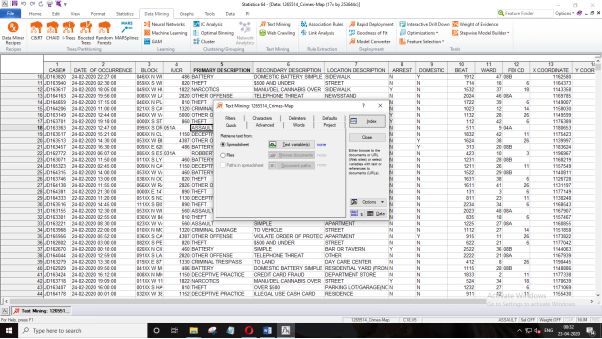
Initially begin with openning the Crime Map data and visit “Text Mining” from the “Data mining” as demonstrated below (Marques De Sa, 2014).
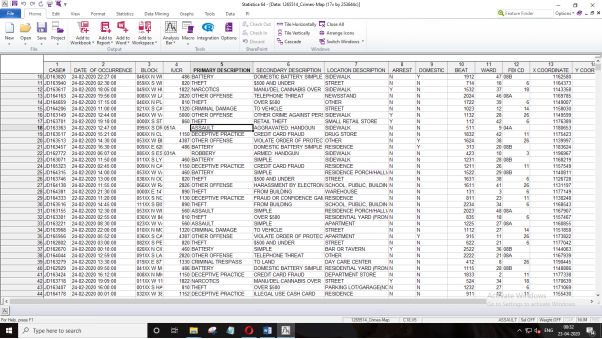
Afterwards, select the variables for Text minig which contains the text by clicking on the Text variable as presented below.
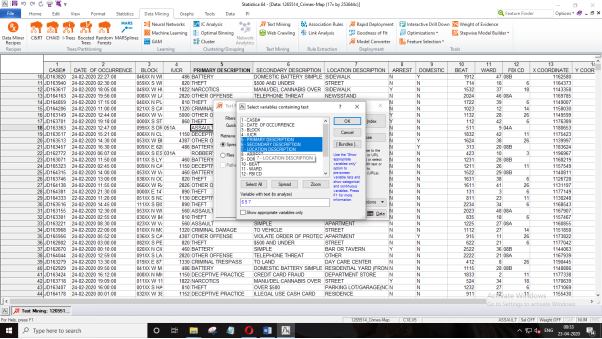
In the text variable selection wizard, select the options “Primary Description”, “Secondary Description”, including the “Location Description” and press on Ok as demonstrated below.
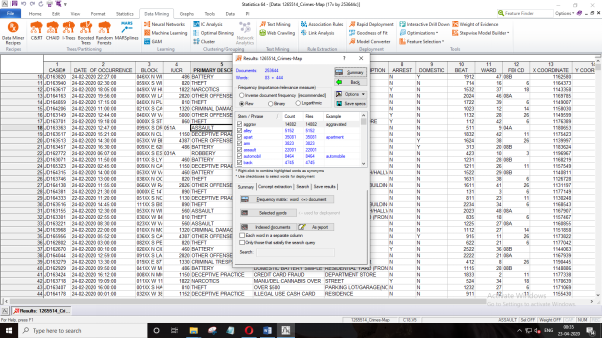
Then, press the OK button, and then select Index. Afterwards, the next screen that displays is the key keywords, followed by the total times they are visible in the dataset as demonstrated below.
Further, in the Result wizard, select Inverse Document Frequency option, next opt “Concept Extraction” tab as presented below.
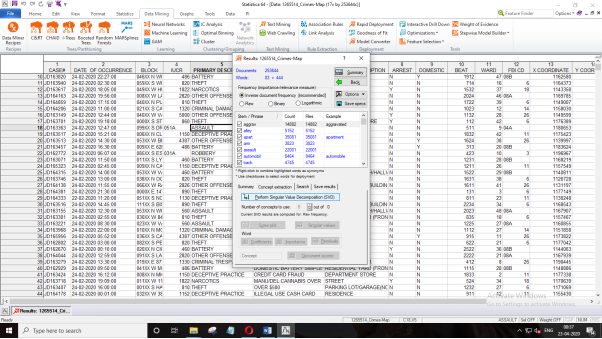
For Concept Extraction, it is required to perform singular value decomposition by clicking “Perform Singular Value Decomposition.”
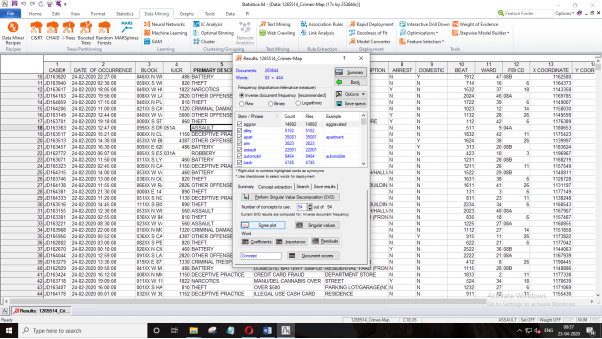
Press Screen Plot option which provides the below graph.
These 4 concepts explains thirty percent of the cases, where the number decreases as there is increase in concepts. Thus, the first four concepts are selected for this analysis. Visit “Text Mining” results screen and press “Save Results” tab. Here, variable amount must be changed as 4. Then, press “Append Empty Variables”, as demonstrated below.
Click on Write back current results, which is used to include the new four variables to the variables list for this analysis by selecting Concepts 1, concepts 2, concept 3 and concepts 4. Further, select NewVar1, NewVar2, NewVar3 and NewVar4. Then, click on “Assign” and OK as presented below.
Boosted Trees
The Boosted trees will be created by clicking on Data Mining select Boosted Trees as demonstrated below.
On Boosted trees, select Classification Analysis and then click on OK as presented below.
Select the variables for the boosted trees by clicking on test variables as presented below.
Then, click on Primary Description variables to be the dependent variable. In continuous variables column, include new variables that are retrieved from text mining. They include – “Concept 1, 2, 3, and 4 as shown below.
Enter the Ok option and it starts STATISTICA for figuring the boost trees as displayed below.
When STATISTICA computation is finished, it gives Boosted Tree Result screen and then visit the Classification tab.
In classification tab, select Lift Chart to provide the results for lift which occurs when text mining is applied to this model as demonstrated below.
The lift chart results are presented below.
The results page show that with text mine option, the unstructured data is enhanced for predicting particular types of crime, for instance, for “Assault,” the prediction ability has been improved with 10 factor, in contrast to the baseline model.
To ensure effective visualization of data i.e., lift charts, it is allowed to merge the graphs. The user can either merge all the graphs to check the specific crime is the highest lift, or could compare more than two graphs simultaneously based on the project’s requirement. Use the right click option for merging the graph, where an option called “merge graph” appear.
Press ok option. Next, once the selection is completed right lift chart. The below graph shows the result.
The user have an option of editing the key by using the right-click option and choosing the Title Properties.
It is possible that a key is re-label by discarding one baseline, including model renaming as “Assault 1.”
It is also possible to modify the line’s colour by choosing each line and right clicking on each, this will ensure that a small window to pop up. Further, proceed by selecting “properties,” and click on “line,” and choose the required colour.
This allows the users to view the positive impact of text mining on the predictive ability for some specific type of crimes. The feature selection finds out the top 3 variables for crime. It is a beneficial analysis for the Chicago Police Department to form the necessary strategies to target their efforts of law enforcement.
Conclusion
It is concluded that the crime data is analyzed effectively with the help of STATISTICA Data Miner and STATISTICA Text Miner. The related instructions and screenshots are included in the report.
References
Marques De Sa, J. (2014). Applied statistics using spss, statistica, matlab and r. New York: Springer.
STATISTICA Text Miner. (2020). Retrieved 23 April 2020, from https://statisticasoftware.wordpress.com/2013/09/18/statistica-text-miner/